
spider共4篇
排序
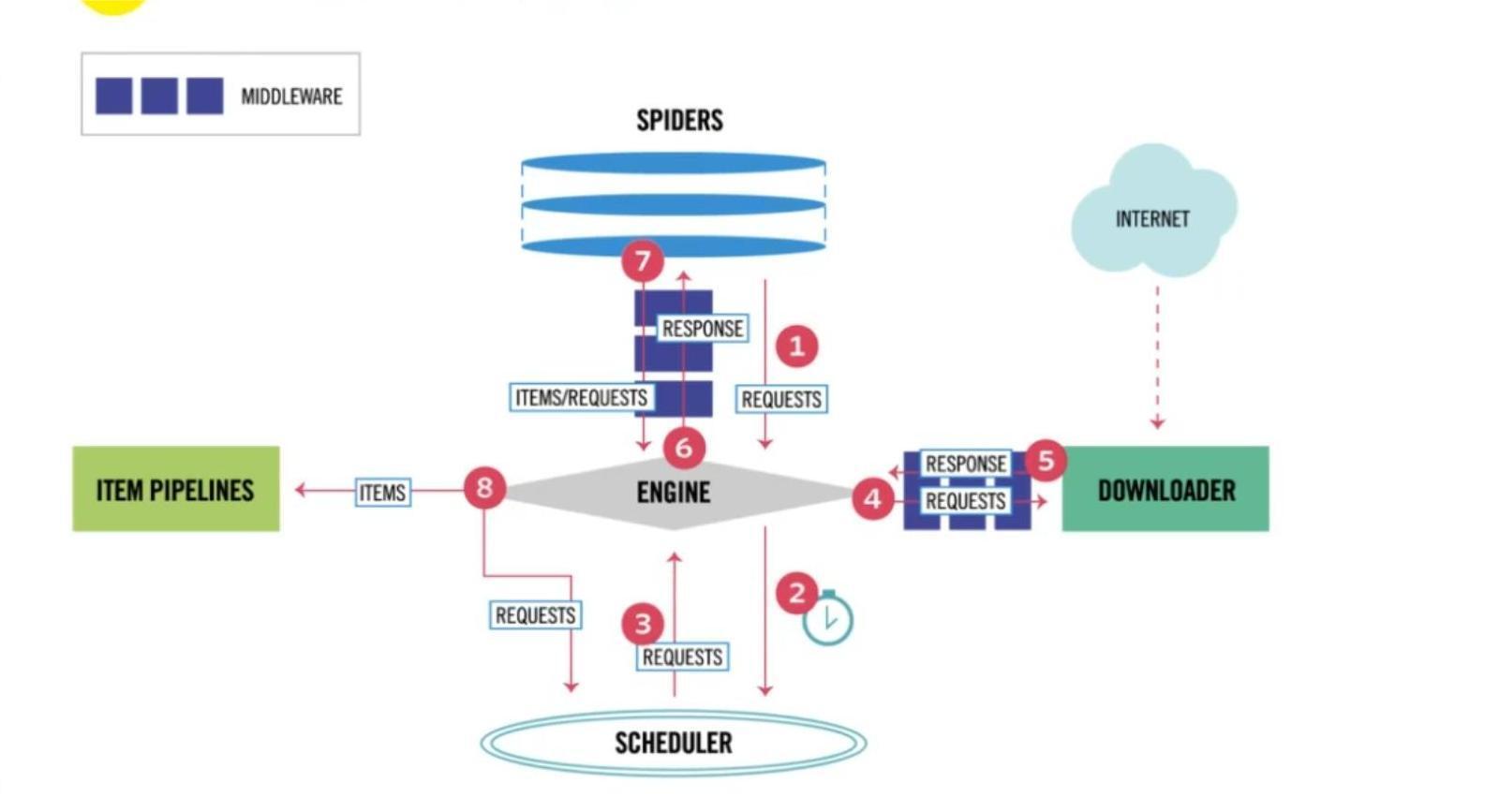
Scrapy框架的基本使用(一)
1、Scrapy概述 当我们写了很多个爬虫程序之后,你会发现每次写爬虫程序时,都需要将页面获取、页面解析、爬虫调度、异常处理、反爬应对这些代码从头至尾实现一遍,这里面有很多工作其实都是...

爬虫简介&requests使用&正则解析数据
一、爬虫简介 1.1 什么是爬虫 爬虫,即网络数据采集,是数据分析的第一步:获取数据 简言之,爬虫可以帮助我们把网站上的信息快速、批量的提取并保存下来。 爬虫(crawler)也经常被称为网络蜘蛛(...
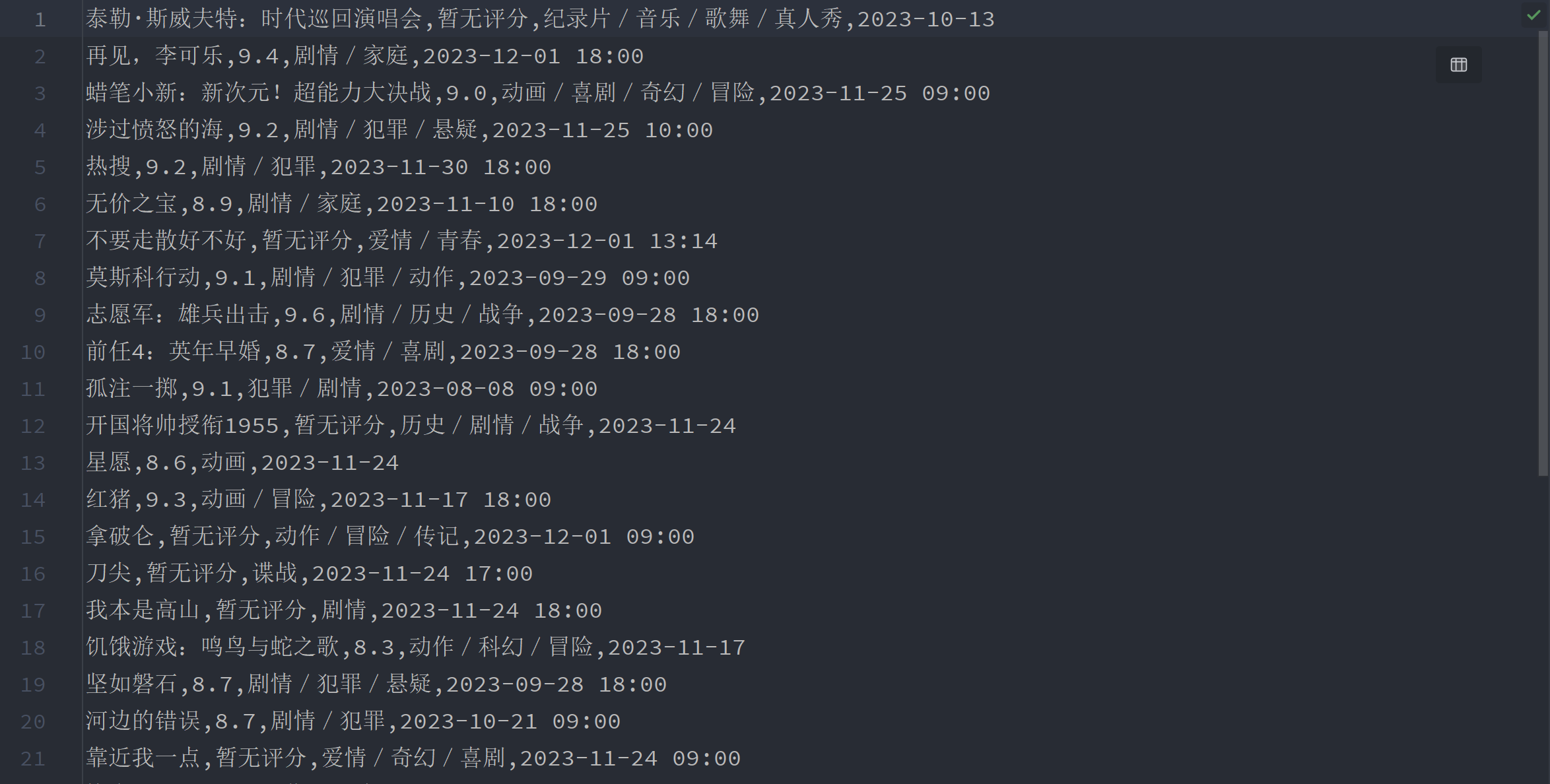
Spider练习(一):提取猫眼电影数据
一、需求 提取猫眼电影首页的数据,网站URL:https://www.maoyan.com/films?showType=3 提取'电影名称', '评分', '电影类型', '电影上映时间'四项内容,并且整理成[['泰勒·斯威夫特:时代...

Web前端简介&HTML&CSS&JS简介
一、Web前端简介 1.1 基本知识 网页主要由三个部分组成: 结构:负责网页的结构和内容,如:标题,图片,段落等,由html实现 表现(样式):设定网页的表现形式,如:标签的位置,大小,文字颜...