一、需求
提取猫眼电影首页的数据,网站URL:https://www.maoyan.com/films?showType=3
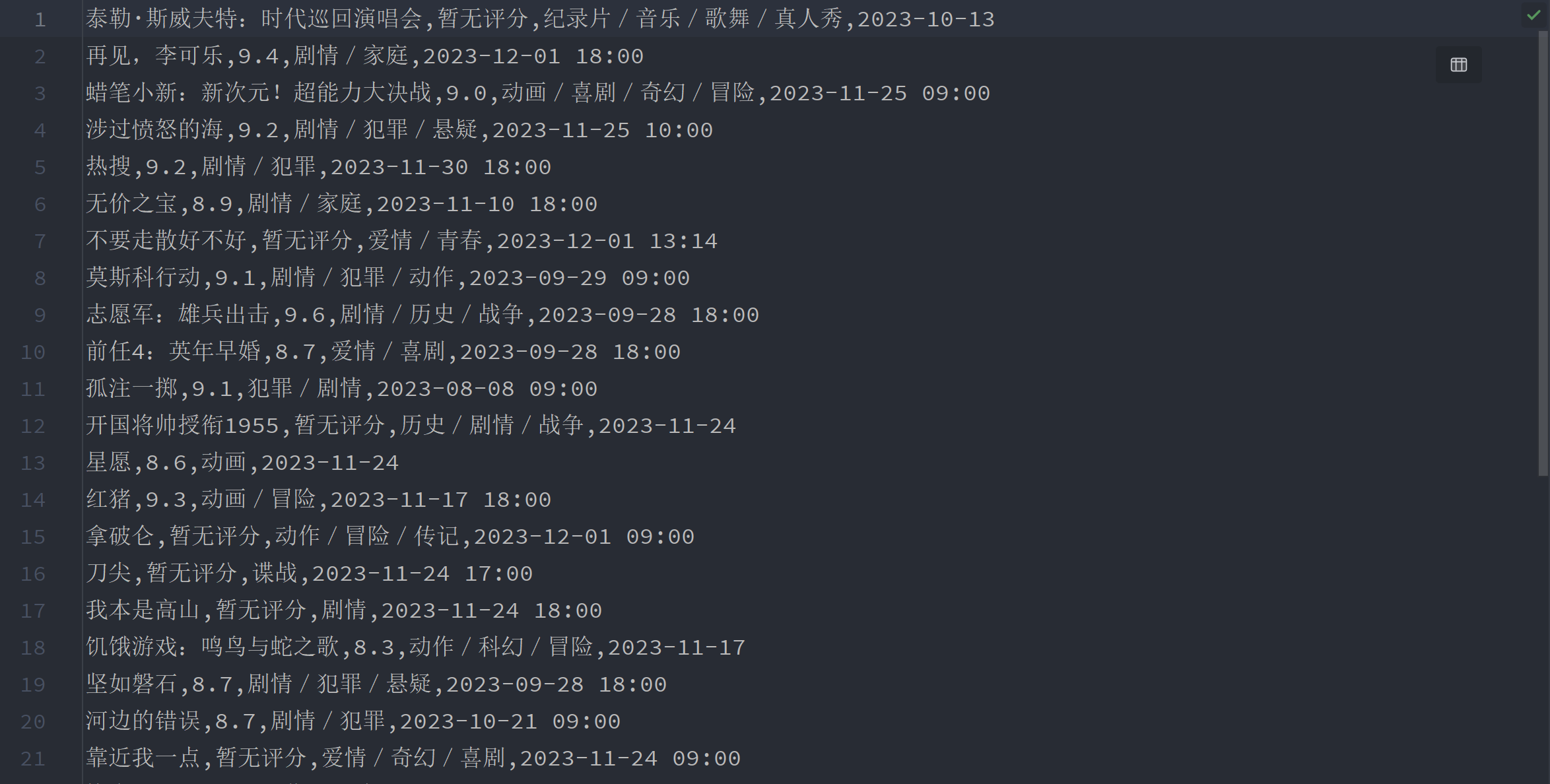
提取'电影名称', '评分', '电影类型', '电影上映时间'四项内容,并且整理成[['泰勒·斯威夫特:时代巡回演唱会', '暂无评分', '纪录片/音乐/歌舞/真人秀', '2023-10-13'],...的格式,然后保存到csv文件中
'电影名称', '评分', '电影类型', '电影上映时间',整理成[['山楂树','9.0','爱情','2010'].....]的格式,并保存到csv文件
二、效果展示
三、代码
# 导入包
import requests, re, csv
# 获取整个网页数据
def get_html():
url = 'https://www.maoyan.com/films?showType=3'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
print(resp.text)
choice_data(resp.text)
else:
print(f"抓取失败,状态码:{resp.status_code}")
# 提取需要的数据
def choice_data(html):
# 电影名称
names = re.findall(r'<div class="movie-hover-title movie-hover-brief" title="(.*?)" ', html)
print(names)
# 评分
scores = re.findall(f'<div class="channel-detail channel-detail-orange">(.*?)</div>', html)
# 定义一个最终评分列表
new_scores = []
# 筛选出有评分的
for score in scores:
result = re.sub(r'<i class="integer">|</i><i class="fraction">|</i>', '', score)
new_scores.append(result)
print(new_scores)
# 电影类型
types = re.findall(r'<span class="hover-tag">类型:</span>\s*(.*?)\s*</div>', html)
print(types)
# 电影上映时间
times = re.findall(r'<span class="hover-tag">上映时间:</span>\s*(.*?)\s*</div>', html)
print(times)
# 数据整合
result = list(map(lambda ele1, ele2, ele3, ele4: [ele1, ele2, ele3, ele4], names, new_scores, types, times))
print(result)
# 调用保存函数
write_csv(result)
# 保存数据到csv
def write_csv(data):
with open(r"猫眼电影.csv", 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)
print("保存成功")
if __name__ == '__main__':
get_html()四、分析
提取网站数据,所以需要用到requests模块,提取指定项内容,需要用到正则表达式,从而需要re模块,最后保存csv文件,需要用到csv模块,所以我们需要用到上述的三个模块
import requests, re, csv然后我们可以定义三个函数,分别用于获取整个网页数据:get_html():,提取需要的数据:choice_data(html):,保存到csv文件:write_csv(data):
首先是用于获取整个网页数据的:get_html():函数,URL,需求中已经给出,所以可以直接定义:url = 'https://www.maoyan.com/films?showType=3'
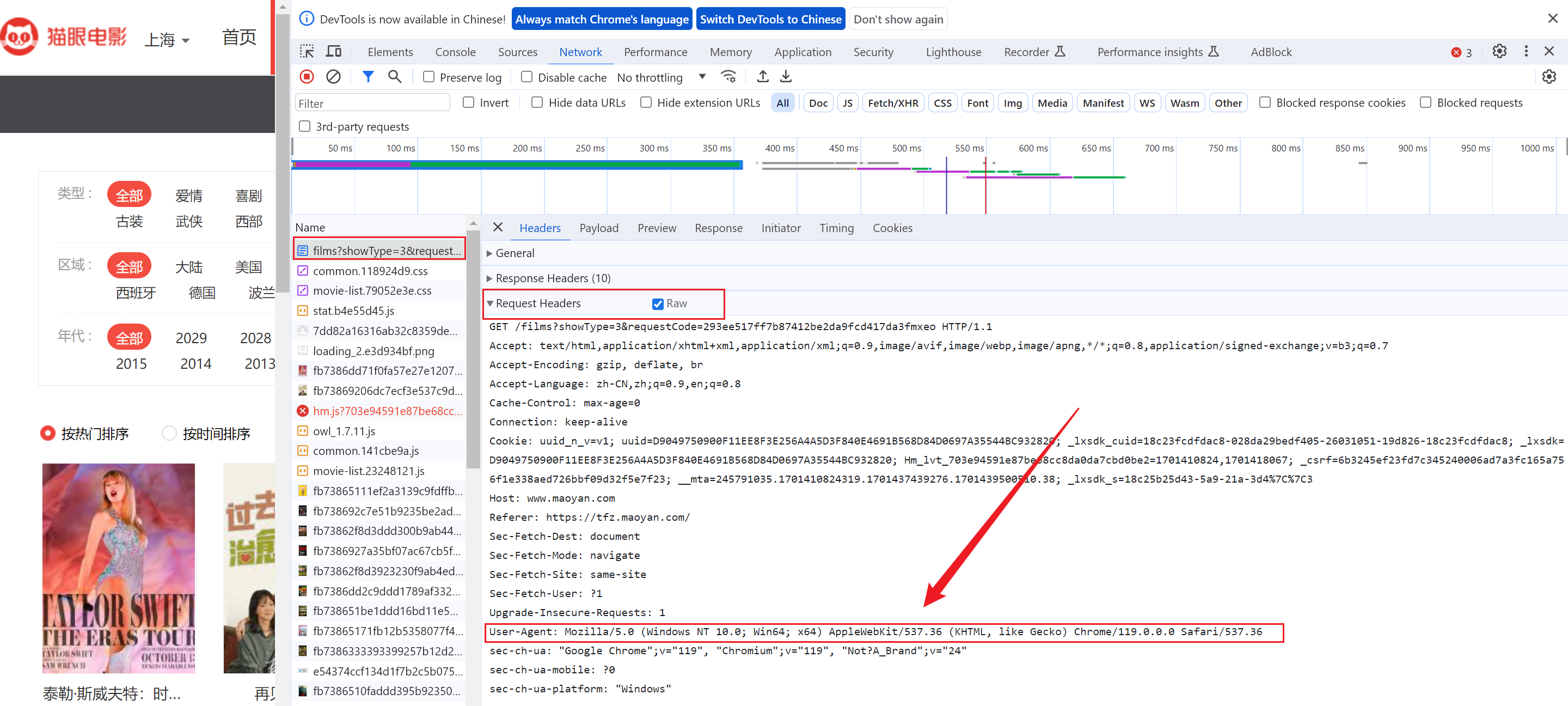
headers可以根据浏览器打开网页,F12查看网页资源,在请求头中有一个参数User-Agent:作用是表标识浏览器的相关信息,足以处理大多数的网站,即
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
需要注意的是,书写的时候一定要写成key:value的形式,即给两部分内容加上引号
然后就可以获取网页资源了
resp = requests.get(url, headers=headers)为了优化代码,可以加一个判断,如果状态码正确,则调用choice_data(resp.text)函数,提取需要的信息,否则则报错,即
if resp.status_code == 200:
print(resp.text)
choice_data(resp.text)
else:
print(f"抓取失败,状态码:{resp.status_code}")下面进行编写choice_data():函数,我们需要分别提取'电影名称', '评分', '电影类型', '电影上映时间'四项内容,由于我们已经在get_html():函数中提取到了,整个网页的内容,结合实际网页观察,我们可以发现
<div class="movie-hover-title movie-hover-brief" title="蜡笔小新:新次元!超能力大决战" >
具有唯一表示,所以调用re.findall()方法,将上诉的代码块作为要搜索匹配的正则表达式,进行匹配,即
names = re.findall(r'<div class="movie-hover-title movie-hover-brief" title="(.*?)" ', html)
print(names)并可以通过print打印检查,至此电影名称提取完成。
下面提取电影评分,观察源代码发现,电影评分分为:暂无评分和有评分两种,并且表达式不一样,其中暂无评分的为:
<div class="channel-detail channel-detail-orange">暂无评分</div>有评分的为
<span class="score channel-detail-orange"><i class="integer">9.</i><i class="fraction">1</i></span>评分还被分成了两部分。
我们可以把<span>中间的所有内容都当成一个整体,从而可以作为第一部提取,即
scores = re.findall(f'<div class="channel-detail channel-detail-orange">(.*?)</div>', html)打印结果
['暂无评分', '暂无评分', '<i class="integer">9.</i><i class="fraction">0</i>',
'<i class="integer">9.</i><i class="fraction">2</i>', '<i class="integer">9.</i><i class="fraction">2</i>',
'<i class="integer">8.</i><i class="fraction">9</i>', '暂无评分',
'<i class="integer">9.</i><i class="fraction">1</i>', '<i class="integer">9.</i><i class="fraction">6</i>',
'<i class="integer">8.</i><i class="fraction">7</i>', '<i class="integer">9.</i><i class="fraction">1</i>',
'暂无评分', '<i class="integer">8.</i><i class="fraction">6</i>',
'<i class="integer">9.</i><i class="fraction">3</i>', '暂无评分', '暂无评分', '暂无评分',
'<i class="integer">8.</i><i class="fraction">3</i>', '<i class="integer">8.</i><i class="fraction">7</i>',
'<i class="integer">8.</i><i class="fraction">7</i>', '暂无评分',
'<i class="integer">6.</i><i class="fraction">6</i>', '暂无评分',
'<i class="integer">9.</i><i class="fraction">3</i>', '<i class="integer">9.</i><i class="fraction">4</i>',
'暂无评分', '<i class="integer">9.</i><i class="fraction">3</i>', '暂无评分',
'<i class="integer">9.</i><i class="fraction">4</i>', '<i class="integer">8.</i><i class="fraction">8</i>']可以发现,暂无评分的没有问题,但是有评分的,字符串中都包含了<i class="integer">、</i><i class="fraction">和</i>,这三部分,所以我们可以用re.sub方法,将这些替换成空字符串,从而得到数字,并将最后的结果放到一个新的列表中,从而使用到for循环
# 定义一个最终评分列表
new_scores = []
# 筛选出有评分的
for score in scores:
result = re.sub(r'<i class="integer">|</i><i class="fraction">|</i>', '', score)
new_scores.append(result)
print(new_scores)至此,评分参数提取结束。还剩下的电影类型和上映时间,提取同理,都比较简单,基本和名称奇趣一致,只有正则表达式有所区别。即
# 电影上映时间
times = re.findall(r'<span class="hover-tag">上映时间:</span>\s*(.*?)\s*</div>', html)
print(times)
# 数据整合
result = list(map(lambda ele1, ele2, ele3, ele4: [ele1, ele2, ele3, ele4], names, new_scores, types, times))
print(result)所以参数提取完后,就需要将数据整合,调用map函数,并且为了方便观察结果,再讲结果转成列表类型,即
# 数据整合
result = list(map(lambda ele1, ele2, ele3, ele4: [ele1, ele2, ele3, ele4], names, new_scores, types, times))
print(result)最后则调用write_csv(data)保存数据函数,采用with表达式即可
with open(r"猫眼电影.csv", 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)






暂无评论内容