一、前言
案例分析:校验合法QQ号
一个合法的QQ号应满足以下条件:1、全部是数字;2、位数5~11位;3、开头不能为0
方法一:使用传统的if判断
def check_qq1(qq: str):
result = True
if qq.isdigit():
if len(qq) in range(5, 12):
if qq.startswith("0"):
result = False
else:
result = False
else:
result = False
return result
if __name__ == '__main__':
qq = "4545455"
r1 = check_qq1(qq)
print(r1)对上诉代码进行简化
def check_qq2(qq: str):
return qq.isdigit() and len(qq) in range(5, 12) and not qq.startswith("0")
if __name__ == '__main__':
qq = "4545455"
r1 = check_qq1(qq)
print(r1)方法二:使用正则表达式
import re
def check_qq3(qq: str):
r = re.match(f"[1-9][0-9]{4, 10}$", qq)
return True if r else False
qq = "12312312"
r3 = check_qq3(qq)
print(r3)二、概念
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。注意:Python中的正则的模块名为re,所以自定义文件的名字不能命名为re
正则表达式的特点:
- 搜索模式可用于文本搜索。如:
search(),findall(),finditer() - 正则表达式是由一个字符序列形成的搜索模式。
- 当你在文本中搜索数据时,你可以用搜索模式来描述你要查询的内容。
- 正则表达式可以是一个简单的字符,或一个更复杂的模式。
- 正则表达式可用于所有文本替换的操作,如:
sub(),subn()
而在python中,通过内嵌集成re模块,可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行
使用场景:
- 用于验证用户名,密码,银行卡号,身份证号,手机号,邮箱,ip地址等
- 爬虫时,使用正则解析网页中的内容
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能
三、单字符匹配
3.1 符号说明
| 单字符匹配符号 | 说明 |
|---|---|
. |
匹配除换行符以外的任意字符 |
[0123456789] |
[]是字符集合,表示匹配方括号中所包含的任意一个字符 |
[good] |
匹配good中任意一个字符 |
[a-z] |
匹配任意小写字母 |
[A-Z] |
匹配任意大写字母 |
[0-9] |
匹配任意数字,类似[0123456789] |
[0-9a-zA-Z] |
匹配任意的数字和字母 |
[0-9a-zA-Z_] |
匹配任意的数字、字母和下划线 |
[^good] |
匹配除了good这几个字母以外的所有字符,中括号里的^称为脱字符,表示不匹配集合中的字符 |
[^0-9] |
匹配所有的非数字字符 |
\d |
匹配数字,效果同[0-9] |
\D |
匹配非数字字符,效果同[^0-9] |
\w |
匹配数字,字母和下划线,效果同[0-9a-zA-Z_] |
\W |
配非数字,字母和下划线,效果同[^0-9a-zA-Z_] |
\s |
匹配任意的空白符(空格,回车,换行,制表,换页),效果同[ \r\n\t\f] |
\S |
匹配任意的非空白符,效果同[^ \f\n\r\t] |
3.2 re模块中函数的调用方式
- 常用的函数
"""
匹配:match()
查找/搜索:search()/findall()/finditer()
替换:sub()/subn()
分割:split()
"""方式一:
import re
pattern = re.compile(r'\d')
r1 = pattern.match('3')
print(r1)方式二(常用)
import re
r2 = re.match(r'\d','3')
print(r2)3.3 .
. :匹配除换行符以外的任意字符
- 默认情况下,
.可以匹配除了换行符以外的任意字符
r1 = re.match(r".", "a")
print(r1) # <re.Match object; span=(0, 1), match='a'>
print(re.match(r".", "\n")) # None- 设置了flags=re.DOTALL,则.可以匹配任意字符,常用于存在大量换行符的文本内容中
r2 = re.match(r".", "\n", flags=re.DOTALL)
print(r2) # <re.Match object; span=(0, 1), match='\n'>3.4 [xxxx]
[xxxxx]:不管[]中书写了多少字符,都只能匹配一位
"""
[0123456789] []是字符集合,表示匹配方括号中所包含的任意一个字符
[good] 匹配good中任意一个字符
[a-z] 匹配任意小写字母
[A-Z] 匹配任意大写字母
[0-9] 匹配任意数字,类似[0123456789]
[0-9a-zA-Z] 匹配任意的数字和字母
[0-9a-zA-Z_] 匹配任意的数字、字母和下划线
"""r1 = re.match(r"[a-z]", "s")
print(r1) # <re.Match object; span=(0, 1), match='s'>
r2 = re.match(r"[2-7a-g]", "3")
print(r2) # <re.Match object; span=(0, 1), match='3'>3.5 [^xxxx]
[^xxxxxx]:称为脱字符,表示不匹配集合中的字符,表示否定
'''
[^good] 匹配除了good这几个字母以外的所有字符,中括号里的^称为脱字符,表示不匹配集合中的字符
[^0-9] 匹配所有的非数字字符
'''# 3.[^xxxxxx]:称为脱字符,表示不匹配集合中的字符,表示否定
r1 = re.match(r"[^0-9]", "a")
print(r1) # <re.Match object; span=(0, 1), match='a'>
r2 = re.match(r"[^0-9]", "3")
print(r2) # None3.6 \d、\D、\W、\w、\s、\S
"""
\d 匹配数字,效果同[0-9]
\D 匹配非数字字符,效果同[^0-9]
\w 匹配数字,字母和下划线,效果同[0-9a-zA-Z_]
\W 匹配非数字,字母和下划线,效果同[^0-9a-zA-Z_]
\s 匹配任意的空白符(空格,回车,换行,制表,换页),效果同[ \r\n\t\f]
\S 匹配任意的非空白符,效果同[^ \f\n\r\t]
""" r1 = re.match(r"\D", "2")
print(r1) # None3.7 练习
需求:匹配一个4位的验证码,每一位都由数字或字母组成
# 需求:匹配一个4位的验证码,每一位都由数字或字母组成
r = re.match(r"[0-9a-zA-Z][0-9a-zA-Z][0-9a-zA-Z][0-9a-zA-Z]", "123s")
print(r) # <re.Match object; span=(0, 4), match='123s'>四、数量词匹配
4.1 符号说明
| 符号 | 说明 |
|---|---|
| x? | 匹配0个或者1个x |
| x* | 匹配0个或者任意多个x(.* 表示匹配0个或者任意多个字符(换行符除外)) |
| x+ | 匹配1个 或者 多个 |
| x{n} | 匹配确定的n个x(n是一个非负整数) |
| x{n,} | 匹配至少n个x |
| x{n,m} | 匹配至少n个最多m个x。注意:n <= m |
4.2 代码说明
# 1.
'''
x{n} 匹配确定的n个x(n是一个非负整数)
x{n,} 匹配至少n个x
x{n,m} 匹配至少n个最多m个x。注意:n <= m
'''
r1 = re.match(r"\d{3}", "698461")
print(r1) # <re.Match object; span=(0, 3), match='698'>
print(r1.group()) # 698
r2 = re.match(r"\d{3,}", "698461aaa231")
print(r2.group()) # 698461
r3 = re.match(r"\d{3,5}", "698461")
print(r3.group()) # 69846# 2.
'''
x? 匹配0个或者1个x
x* 匹配0个或者任意多个x(.* 表示匹配0个或者任意多个字符(换行符除外))
x+ 匹配1个 或者 多个
'''
r1 = re.match(r"\d?", "698461")
print(r1) # <re.Match object; span=(0, 3), match='6'>
print(r1.group()) # 6
r2 = re.match(r"\d*", "698461aaa231")
print(r2.group()) # 698461
r3 = re.match(r"\d*", "698461")
print(r3.group()) # 698461Match对象.group():获取到匹配的字符串
match():匹配,从左往右依次匹配,如果匹配上,返回Match对象,如果匹配不上,返回None
search():搜索,底层和match的使用相同,如果搜索到,返回Match对象,如果搜索不上,返回None
注:只要搜索到一个符合条件的子字符串,则停止搜索
findall():查找所有,最终的结果返回一个列表
r1 = re.match(r'\d+','a5636fafa372qw76a627jky277')
print(r1) # None
r1 = re.search(r'\d+','a5636fafa372qw76a627jky277')
print(r1) # 5636
r1 = re.findall(r'\d+','a5636fafa372qw76a627jky277')
print(r1) # ['5636', '372', '76', '627', '277']4.3 练习
需求:匹配一个4位的验证码,每一位都由数字或字母组成
之前的代码
# 需求:匹配一个4位的验证码,每一位都由数字或字母组成
r = re.match(r"[0-9a-zA-Z][0-9a-zA-Z][0-9a-zA-Z][0-9a-zA-Z]", "123s")
print(r) # <re.Match object; span=(0, 4), match='123s'>现在的代码
r = re.match(r'[a-zA-Z0-9]{4}','4f28')
print(r)五、边界匹配
5.1 符号说明
| 符号 | 说明 |
|---|---|
| ^ | 行首匹配,和在[]里的^不是一个意思 |
| $ | 行尾匹配 |
| \A | 匹配字符串开始,它和^的区别是,\A只匹配整个字符串的开头,即使在re.M模式下也不会匹配它行的行首 |
| \Z | 匹配字符串结束,它和$的区别是,\Z只匹配整个字符串的结束,即使在re.M模式下也不会匹配它行的行尾 |
5.2 ^和$
^ 行首匹配,和在[]里的^不是一个意思
$ 行尾匹配- 默认情况下,字符串使用的是单行模式,哪怕字符串中包含了
\n换行符
r1 = re.findall(r"^this", 'this is a test\nthis is a test\nthis is a test')
print(r1) # ['this']
r1 = re.findall(r"test$", 'this is a test\nthis is a test\nthis is a test')
print(r1) # ['test']- 如果需要匹配到多行的行首或行尾,则需要设置
flags=re.M或flags=re.MULTILINE,才表示多行模式
r1 = re.findall(r"^this", 'this is a test\nthis is a test\nthis is a test', flags=re.M)
print(r1) # ['this', 'this', 'this']
r1 = re.findall(r"test$", 'this is a test\nthis is a test\nthis is a test', flags=re.MULTILINE)
print(r1) # ['test', 'test', 'test']$经常用于位数的限制中
应用:验证qq号
qq = '56276187561875618'
r = re.match(r"[1-9]\d{4,10}$", qq) # [1-9][0-9]{4,10}
print(r) # None5.3 \A和\Z
\A 匹配字符串开始,它和^的区别是,\A只匹配整个字符串的开头,即使在re.M模式下也不会匹配它行的行首
\Z 匹配字符串结束,它和$的区别是,\Z只匹配整个字符串的结束,即使在re.M模式下也不会匹配它行的行尾r1 = re.findall(r"\Athis", 'this is a test\nthis is a test\nthis is a test')
print(r1) # ['this']
r1 = re.findall(r"test\Z", 'this is a test\nthis is a test\nthis is a test')
print(r1) # ['test']
r1 = re.findall(r"\Athis", 'this is a test\nthis is a test\nthis is a test', flags=re.M)
print(r1) # ['this']
r1 = re.findall(r"test\Z", 'this is a test\nthis is a test\nthis is a test', flags=re.MULTILINE)
print(r1) # ['test']六、分组匹配
6.1 符号说明
| 符号 | 说明 |
|---|---|
| x|y | |表示或,匹配的是x或y |
| (xyz) | 匹配小括号内的xyz(作为一个整体去匹配) |
6.2 代码说明
- 原代码
print(re.findall(r"\d+",'s472475-gjhgah3475987aksp194'))
print(re.findall(r"[a-z]+",'s472475-gjhgah3475987aksp194'))输出结果
['472475', '3475987', '194']
['s', 'gjhgah', 'aksp']- 使用
x|y
print(re.findall(r"\d+|[a-z]+",'s472475-gjhgah3475987aksp194'))输出结果
['s', '472475', 'gjhgah', '3475987', 'aksp', '194']- 使用
(xyz)——捕获型分组
print(re.findall(r"(\d+)|[a-z]+",'s472475-gjhgah3475987aksp194'))
print(re.findall(r"\d+|([a-z]+)",'s472475-gjhgah3475987aksp194'))输出结果
['', '472475', '', '3475987', '', '194']
['s', '', 'gjhgah', '', 'aksp', '']- 非捕获型分组:
(?:xxx): 这是一个非捕获组的语法,它用于创建一个分组,但不会捕获该分组的匹配结果。
print(re.findall(r"(?:\d+)|[a-z]+",'s472475-gjhgah3475987aksp194'))
print(re.findall(r"\d+|(?:[a-z]+)",'s472475-gjhgah3475987aksp194'))输出结果
['s', '472475', 'gjhgah', '3475987', 'aksp', '194']
['s', '472475', 'gjhgah', '3475987', 'aksp', '194']finditer():区别于findall,返回迭代器
r1 = re.finditer(r"(\d+)|[a-z]+",'s472475-gjhgah3475987aksp194')
print(r1)输出结果
<callable_iterator object at 0x0000020F0AD97EB0>获取数据,通过转列表或遍历
print(list(r1))
print([ele.group() for ele in r1])七、贪婪匹配和非贪婪匹配
数量词匹配中
x? 匹配0个或者1个x
x* 匹配0个或者任意多个x(.* 表示匹配0个或者任意多个字符(换行符除外))
x+ 匹配1个 或者 多个+和*都是贪婪匹配,会尽可能多的匹配- 如果只有在正则表达式的前面出现限制条件,在
+或*的后面添加?,可以将贪婪匹配转换为非贪婪匹配- 即:
+?或*?:可以将贪婪匹配转化为非贪婪匹配
- 即:
- 在爬虫中,
re.findall(r".+?img.+?src=(.+?)","xxxxxxxx",flags=re.DOTALL)
# 1.
r1 = re.match(r'\d?', '5626277225266627277')
print(r1.group()) # 5
r1 = re.match(r'\d+', '5626277225266627277')
print(r1.group()) # 5626277225266627277
r1 = re.match(r'\d*', '5626277225266627277')
print(r1.group()) # 5626277225266627277
# 2.
print(re.findall(r"s\w", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"\wh", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"s\wh", 's472475_gjhgah3475987aksp194h'))
"""
['s4', 'sp']
['jh', 'ah', '4h']
[]
"""
print(re.findall(r"s\w?", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"\w?h", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"s\w?h", 's472475_gjhgah3475987aksp194h'))
"""
['s4', 'sp']
['jh', 'ah', '4h']
[]
"""
print(re.findall(r"s\w+", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"\w+h", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"s\w+h", 's472475_gjhgah3475987aksp194h'))
"""
['s472475_gjhgah3475987aksp194h']
['s472475_gjhgah3475987aksp194h']
['s472475_gjhgah3475987aksp194h']
"""
print(re.findall(r"s\w*", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"\w*h", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"s\w*h", 's472475_gjhgah3475987aksp194h'))
"""
['s472475_gjhgah3475987aksp194h']
['s472475_gjhgah3475987aksp194h']
['s472475_gjhgah3475987aksp194h']
"""
print(re.findall(r"s\w+?", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"\w+?h", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"s\w+?h", 's472475_gjhgah3475987aksp194h'))
"""
['s4', 'sp']
['s472475_gjh', 'gah', '3475987aksp194h']
['s472475_gjh', 'sp194h']
"""
print(re.findall(r"s\w*?", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"\w*?h", 's472475_gjhgah3475987aksp194h'))
print(re.findall(r"s\w*?h", 's472475_gjhgah3475987aksp194h'))
"""
['s', 's']
['s472475_gjh', 'gah', '3475987aksp194h']
['s472475_gjh', 'sp194h']
"""八、常用函数
-
compile()
- 将正则字符串编译成正则对象,一般都是为了结合其他 函数使用
-
match()
- 用正则匹配指定字符串中的内容,如果匹配上,返回Match对象,如果未匹配上,则返回None
- 应用:判断用户名或密码是否合法
-
search()
- 用正则搜索指定字符串中的内容,如果匹配上,返回Match对象,如果未匹配上,则返回None
- 注:只会查找一次
-
findall()
- 用正则搜索指定字符串中的内容,如果匹配上,返回非空列表,如果未匹配上,则返回[]
- 应用:全局搜索数据,在爬虫中一般使用findall
r = re.findall(r"a\d","6a8ghjaga3474a9") print(r) # ['a8', 'a3', 'a9'] -
finditer()
- 用正则搜索指定字符串中的内容,返回一个迭代器,如果匹配上,则迭代器中的元素为Match对象
- 注:查找所有
r = re.finditer(r"a\d","6a8ghjaga3474a9") print(r) #-
获取对象数据
-
方式一:遍历
for obj in r: print(obj) print(obj.group()) # 获取Match对象的文本内容- 方式二:next()
print(next(r)) print(next(r)) print(next(r)) -
split()
- 用正则指定的规则分割指定字符串,返回一个列表
str1 = 'one1two1three1four' l1 = str1.split("1") # 字符串.split(分割符),返回一个列表,适用于分割有规律的字符串 print(l1) str1 = 'one1two6three3four' l1 = re.split(r'\d',str1) # re.split(正则分割符,字符串) print(l1) str1 = 'one1466two624492236three354four' l1 = re.split(r'\d+',str1) print(l1) # 同字符串.split(),re.split()也可以指定分割次数 str1 = 'one1466two624492236three354four' l1 = re.split(r'\d+',str1,2) print(l1)- 练习:挑出下面字符串中的人名
names = 'zhangsan######Jack@@TOM&&&&&&&&&bob' r = re.findall(r"\w+",names) print(r) r = re.split(r"[#@&]+",names) print(r) r = re.split(r"[^a-zA-Z]+",names) print(r) -
sub()
- 将正则匹配到的子字符串用指定字符串进行替换
str1 = 'one34628two5558252three16266four' l1 = re.sub(r"\d+",'-',str1) print(l1)等同于
str1 = 'one111two111three111four' l1 = str1.replace('111',"-") print(l1)- 可以指定替换的次数
str1 = 'one34628two5558252three16266four' l1 = re.sub(r"\d+",'-',str1,2) print(l1) -
subn()
- 将正则匹配到的子字符串用指定字符串进行替换
- 返回一个元组,格式:(新字符串,替换的次数)
str1 = 'one34628two5558252three16266four' l1 = re.subn(r"\d+",'-',str1) print(l1) # ('one-two-three-four', 3)
九、练习
9.1 练习一
用户名匹配
1.用户名只能包含数字 字母 下划线
2.不能以数字开头
3.⻓度在 6 到 16 位范围内import re
def check_username(username):
r = re.match(r"[^0-9]\w{5,15}$", username)
return True if r else False
result = check_username("12345678")
print(result)9.2 练习二
密码匹配
1.不能包含!@#¥%^&*这些特殊符号
2.必须以字母开头
3.⻓度在 6 到 12 位范围内import re
def check_pwd(pwd):
r = re.match(r"[a-zA-Z][^!@#¥%^&*]{5,11}$", pwd)
return True if r else False
result = check_pwd("a1a2345678")
print(result)9.3 练习三
将给定字符串中的数字挑出,拼接成一个新的字符串
- 方式一:
import re
def select_num(char):
r = re.findall(r"\d+", char)
new_char = "".join(r)
return new_char
result = select_num("123abc456abc780qwe")
print(result)- 方式二
import re
def select_num(char):
r = re.split(r"\D+", char)
code = "".join(r)
return code
result = select_num("123abc456abc780qwe")
print(result)9.4 练习四
将给定字符串中的数字挑出,求和
- 方式一
import re
def select_num(char):
r = re.findall(r"\d+", char)
total = sum([int(num) for num in r])
return total
result = select_num("123abc456abc780qwe")
print(result)- 方式二
import re
def select_num(char):
r = re.split(r"\D+", char)
total = sum([int(num) for num in r if num != ""])
return total
result = select_num("123abc456abc780qwe")
print(result)十、正则在爬虫的应用
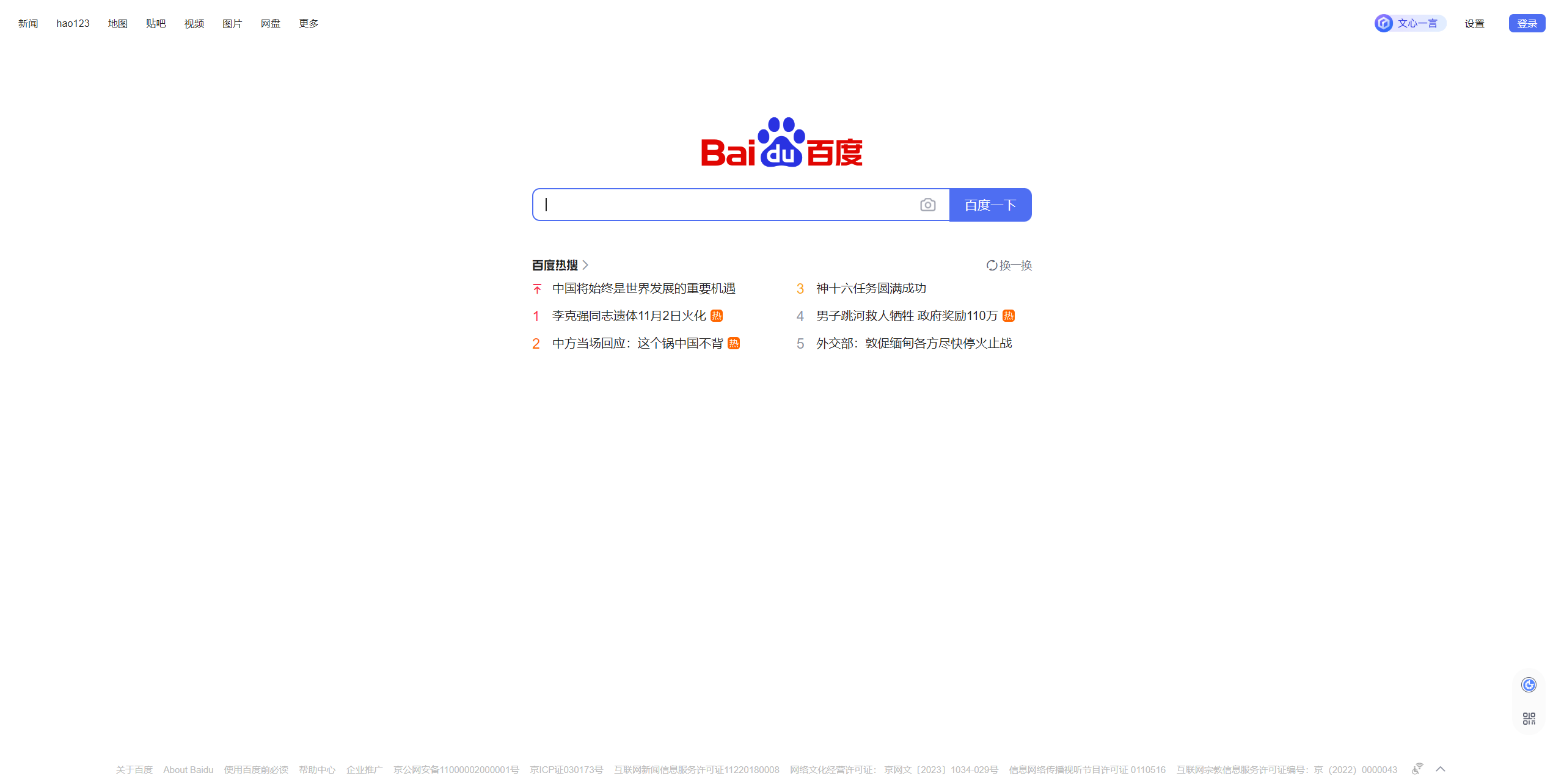
爬取https://www.baidu.com/页面
import re
import requests
url = "https://www.baidu.com/"
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
print("请求成功~~~~~~~~")
# print(response.text) # 全部内容
regex_str = '<span class="title-content-title">(.+?)</span>'
r = re.findall(regex_str, response.text)
print(r)
else:
print(f"请求失败:{response.status_code}")输出结果
请求成功~~~~~~~~
['中国将始终是世界发展的重要机遇', '神十六任务圆满成功', '李克强同志遗体11月2日火化', '男子跳河救人牺牲 政府奖励110万', '中方当场回应:这个锅中国不背', '985毕业生在英国富人区做保姆']





暂无评论内容