一、Selenium获取Scrape图书信息
1.1 需求
需求:使用Selenium请求Scrape图书网站1-10页,使用bs4或xpath解析数据
获取"书名", "评分", "标签", "价格", "作者", "发表时间", "出版商", "页数", "ISBM编号"信息,并实现数据持久化
URL:https://spa5.scrape.center/page/1
1.2 解决方案
1.2.1 Requests获取图书数据
a. 分析
首先,打开网站,然后配合F12检查元素,可以发现,当前网站是一个动态数据,直接请求,拿不到数据
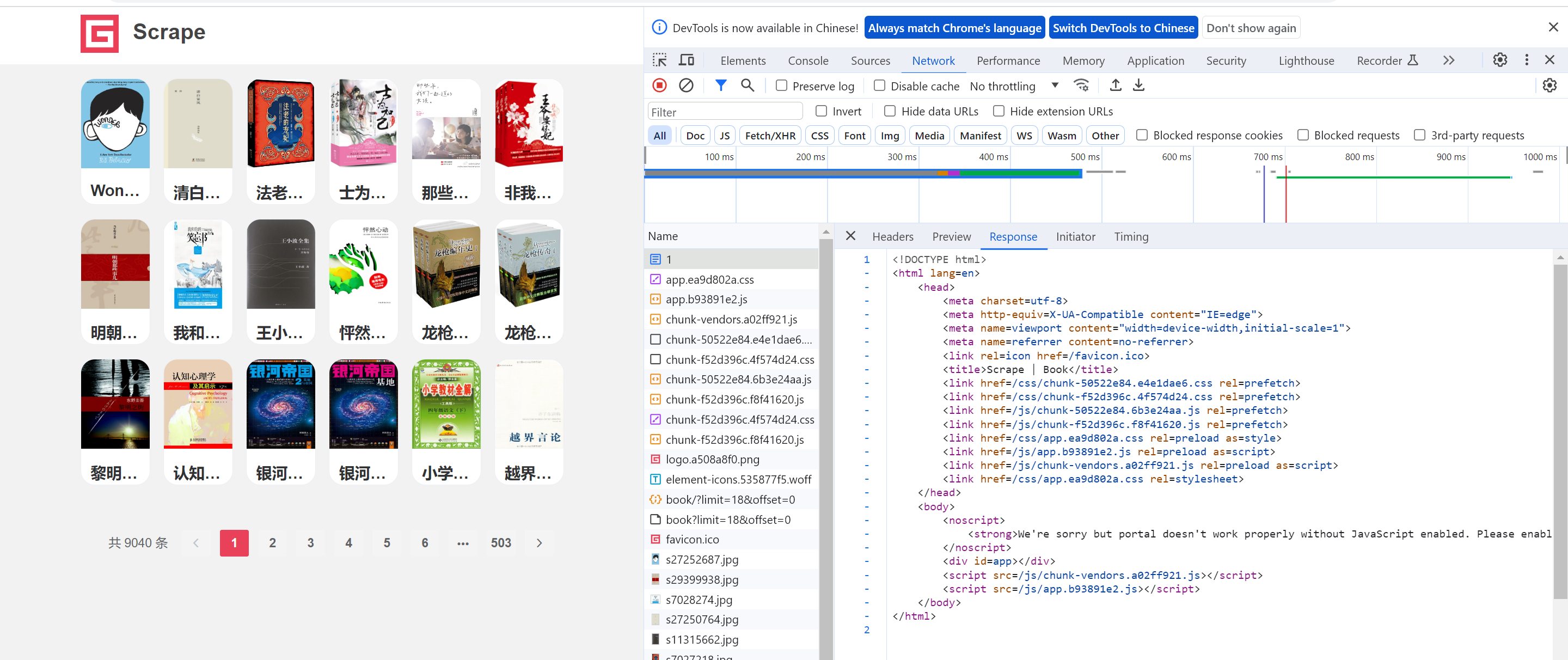
然后我们分析,网页请求Fetch API,在这里面有一个文件,里面存放着数据,并且是一个JSON格式

所以我们就可以直接请求该文件的URL
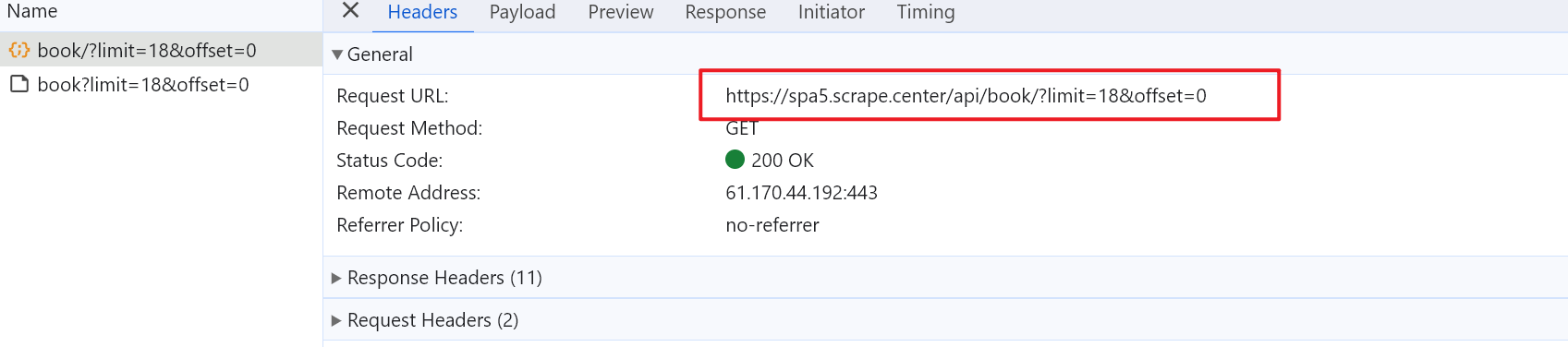
就能拿到数据,但是,我们需要更多的详细数据,这些数据存放在书籍的详情页中。在观察数据详情页的网页元素,可以发现,该网页也还是一个动态数据,文件同样存放在JSON中。但是通过刚才获取到的数据,其中有一个KEY——count,其对应的值,刚好为书籍详情信息的JSON的URL的最后一部分,从而可以拿到所有的详情页JSON的URL,从而从JSON中解析各个数据,最后保存到文件中,实现持久化。
核心:Requests请求 + JSON解析
b . 完整代码
# 1.请求数据
def get_data():
# 说明:通过给定的url发现,请求到的结果不对,从而判断当前网站的数据是动态的
for i in range(10):
# 动态数据,动态页面
url = f"https://spa5.scrape.center/api/book/?limit=18&offset={0 * 18}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/119.0.0.0 Safari/537.36'
}
# 请求数据
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
print(f"第{i + 1}页请求成功")
books_list = resp.json().get("results")
parse_data(books_list)
# 2.解析数据
def parse_data(data):
book_messages = []
# 需要的数据在详情页中,其中ID对应的值为URL的最后一部分。所以,获取详情页,在详情页中在请求数据,然后解析
for book in data:
# 还是动态数据,动态页面
# 获取书籍详情页URL:实际URL前缀:https://spa5.scrape.center/api/book/
book_url = f"https://spa5.scrape.center/api/book/{book.get('id')}"
# 请求数据
book_resp = requests.get(book_url)
# 判断是否拿到数据
if book_resp.status_code == 200:
print(f"编号{book.get('id')}的详情页请求成功")
book_dict = book_resp.json()
# a.获取书名
book_name = book_dict.get("name")
# b.获取评分
book_score = book_dict.get("score")
# c.获取标签
book_tags = "-".join(book_dict.get("tags"))
# d.获取定价
book_price = book_dict.get("price")
# e.获取作者
book_author = "/".join([item.strip() for item in book_dict.get("authors")])
# f.出版时间
book_published_at = book_dict.get("published_at")
# g.获取出版社
book_publisher = book_dict.get("publisher")
# h.获取页数
book_page_number = book_dict.get("page_number")
# i.获取ISBM编号
book_isbn = book_dict.get("isbn")
# 整合数据
book_messages.append(
[book_name, book_score, book_tags, book_price, book_author, book_published_at, book_publisher,
book_page_number, book_isbn])
# 保存数据
save_data(book_messages)
# 3.保存数据
def save_data(data_list):
for item in data_list:
sheet.append(item)
if __name__ == '__main__':
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["书名", "评分", "标签", "价格", "作者", "发表时间", "出版商", "页数", "ISBM编号"])
get_data()
wb.save("Scrape图书1-10页.xlsx")1.2.2 Selenium获取图书数据
a.分析
通过界面的分析,我么知道这是一个动态的网页数据,Selenium是web的自动化测试工具,模拟人操作浏览器的行为,我们要先打开浏览器,然后点击一本书的详情页,然后刷选数据信息,数据获取后,在返回到主网页中,继续点击下一本的数据操作,直到这一个网页中所有的图书信息获取完毕,然后点击下一页。
这里就涉及到了两个点击行为:进入下一页和返回上一页,对应的Selenium中有两个方法click()和back()
同时,每次在进入一个网站的时候,建议添加一句,time.sleep(3),让程序休眠几秒,渲染网页
b.实现
首先程序整体可以分为三个部分和一个mian代码块
- 获取数据:
get_data() - 解析数据:
parse_data() - 保存数据:
save_data()
下面对每一个部分具体分析
(1) 获取数据:get_data()
这里我们使用Selenium的方式请求数据,所以我们首先需要创建一个浏览器对象
browser = webdriver.Chrome()然后设置窗口最大化
browser.maximize_window()然后调用get()方法传入URL
url = "https://spa5.scrape.center"
browser.get(url)此时浏览器会执行操作,打开网页,所以我们要让程序休眠几秒,用于渲染网页
time.sleep(3)下面就可以调用获取数据函数:parse_data(),然后关闭浏览器即可
parse_data(browser)
# 关闭窗口
browser.close()(2) 解析数据:parse_data()
这里就负责解析数据,我们首先进入的是主网页,然后配个F12检查元素视角,定位每一本图书都在一个div中,
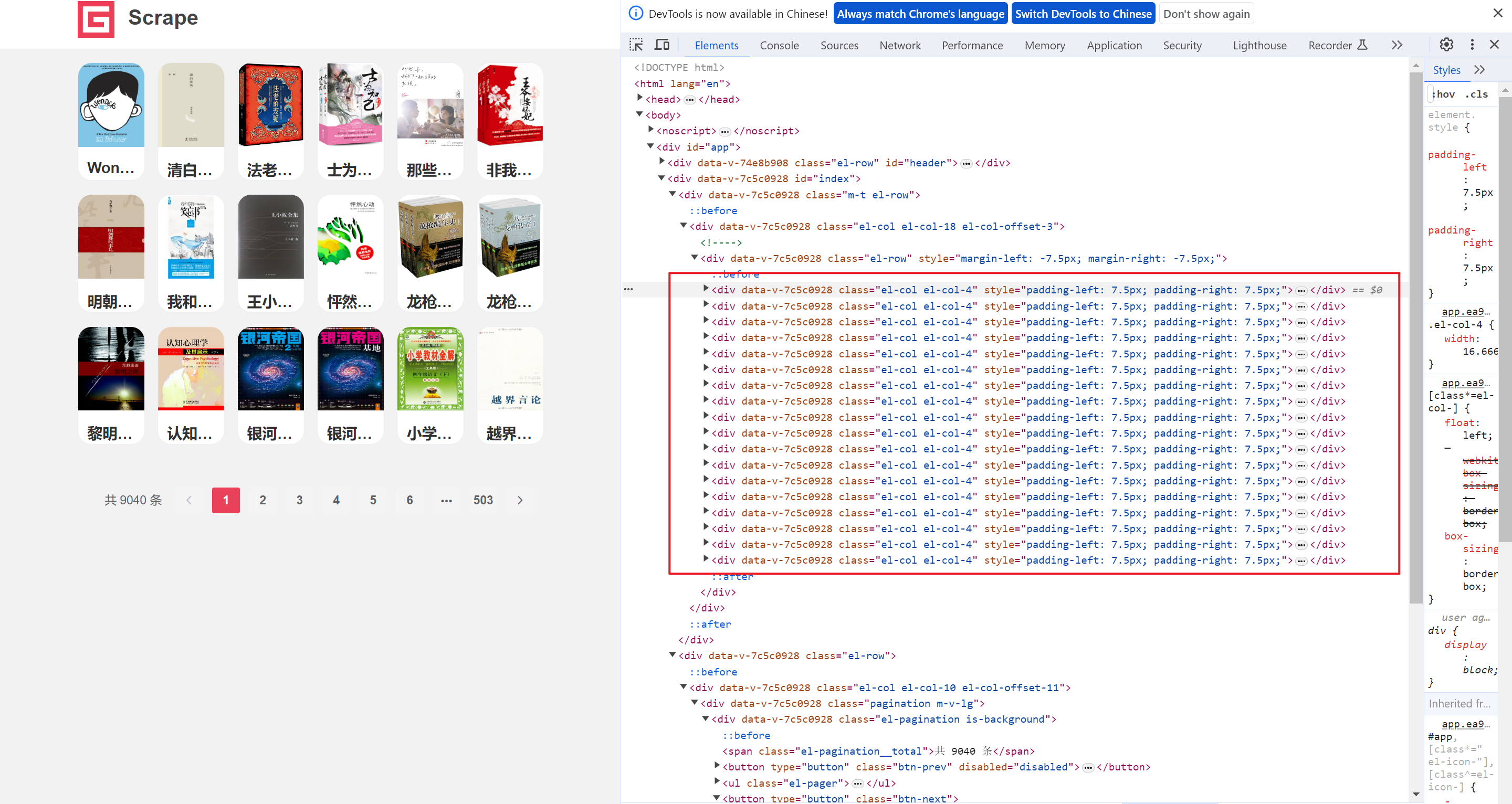
但是,为了准确定位,我们要选择具有唯一标识的DIV,所以我们依次往上查看父类DIV,直到选择到合适的为止。
这里,我们选择的是XPATH方式解析,语法为
这里需要导入一个额外的模块
from selenium.webdriver.common.by import By
"""find_element(by,value):
find_elements(by,value):
其中by的值:
by:
ID:id,通过标签的id属性值进行查找
XPATH:表示根据xpath路径规则进行定位
CSS_SELECTOR:根据css选择器进行定位
LINK_TEXT:通过a标签的内容获取标签(只针对a标签)
value:方式对应的值"""# 获取所有的图书
books_list = browser.find_elements(by=By.XPATH,
value="//div[@class='m-t el-row']/div/div/div")获取到了每一本书的DIV,我们就可以使用for循环进行遍历,因为需要进入到详情页获取数据,所以需要点击div,
# for循环,获取一页的数据
for pos in range(1, len(books_list) + 1):
# 因为需要进入到详情页获取数据,所以点击div
book_div = browser.find_element(by=By.XPATH,value=f"//div[@class='m-t el-row']/div/div/div[{pos}]")
book_div.click() # 效果相当于鼠标的左键单击
# 休眠几秒,渲染页面
time.sleep(3)下面就可以配合检查视角,获取具体数据了
- 获取图书名称
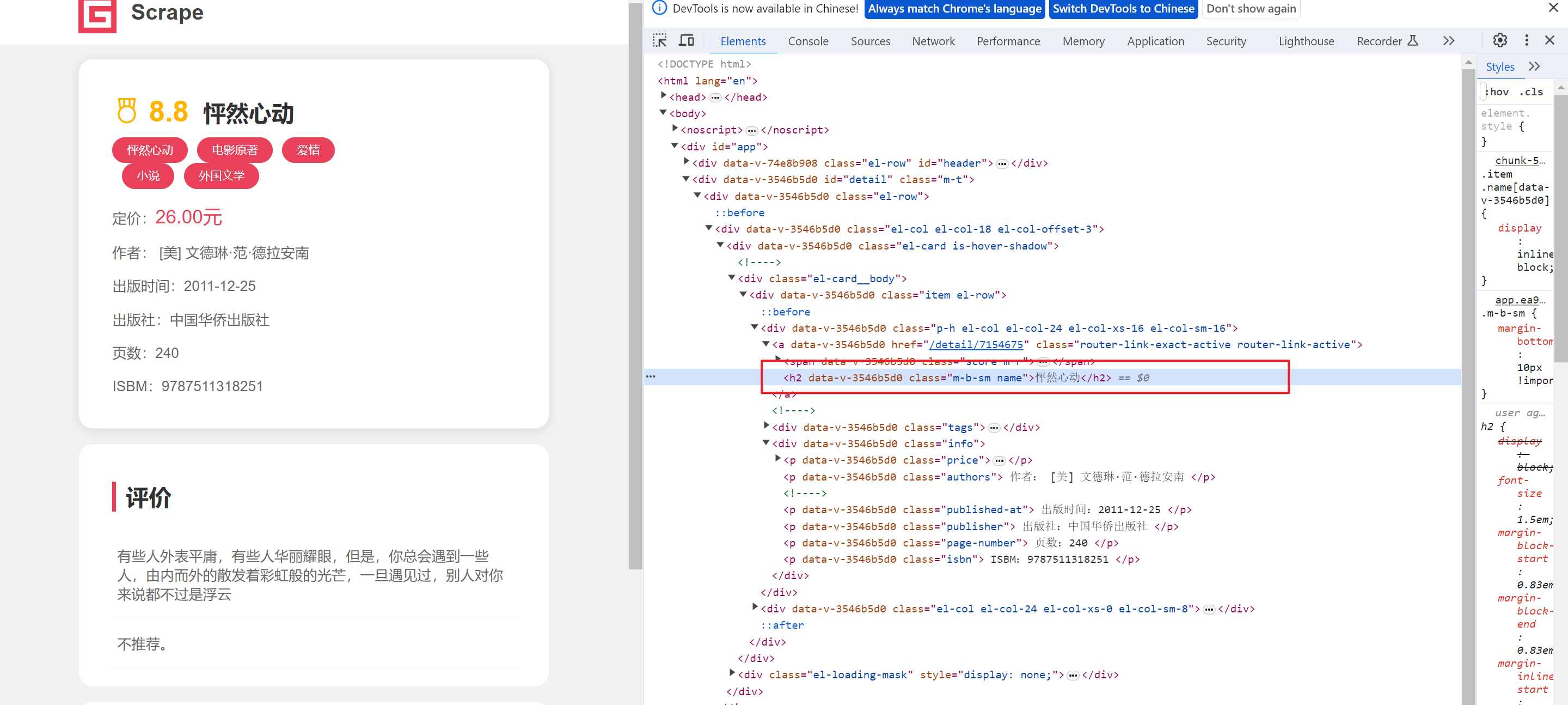
book_name = browser.find_element(by=By.XPATH, value="//h2[@class='m-b-sm name']").text- 获取图书评分
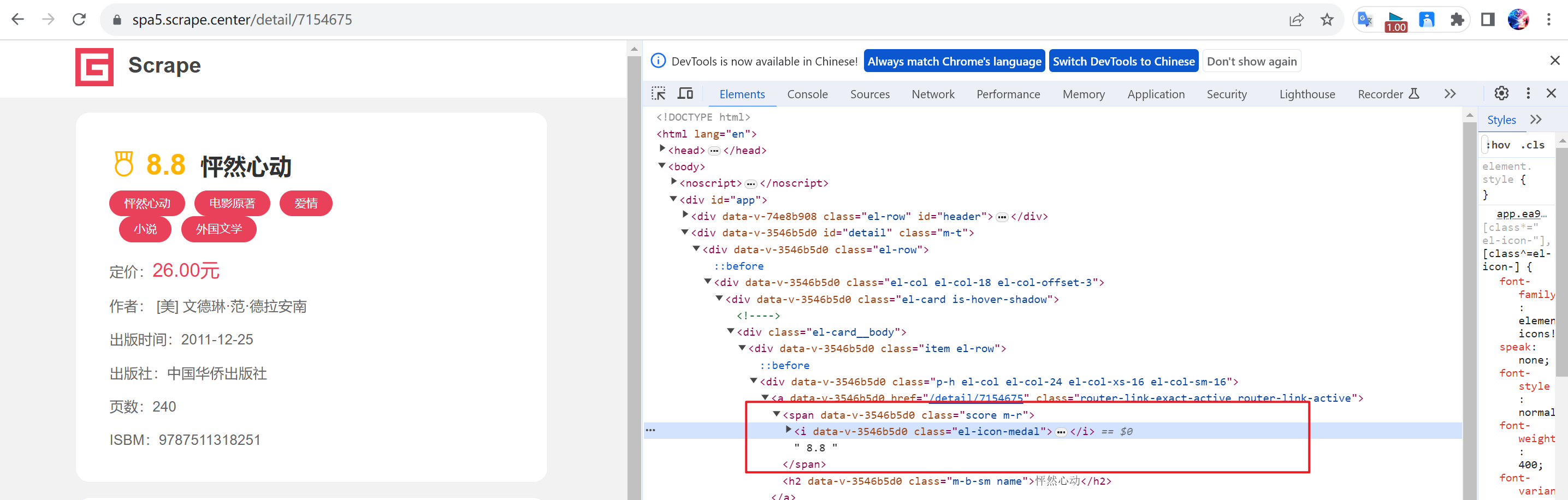
book_score = browser.find_element(by=By.XPATH, value="//span[@class='score m-r']").text- 获取标签
这里需要注意,标签是多个,所以我们要使用find_elements(),返还是一个列表,然后使用字符串进行拼接

book_tags = browser.find_elements(by=By.XPATH, value="//div[@class='tags']/button")
book_tags = "-".join([tag.text for tag in book_tags])- 获取定价
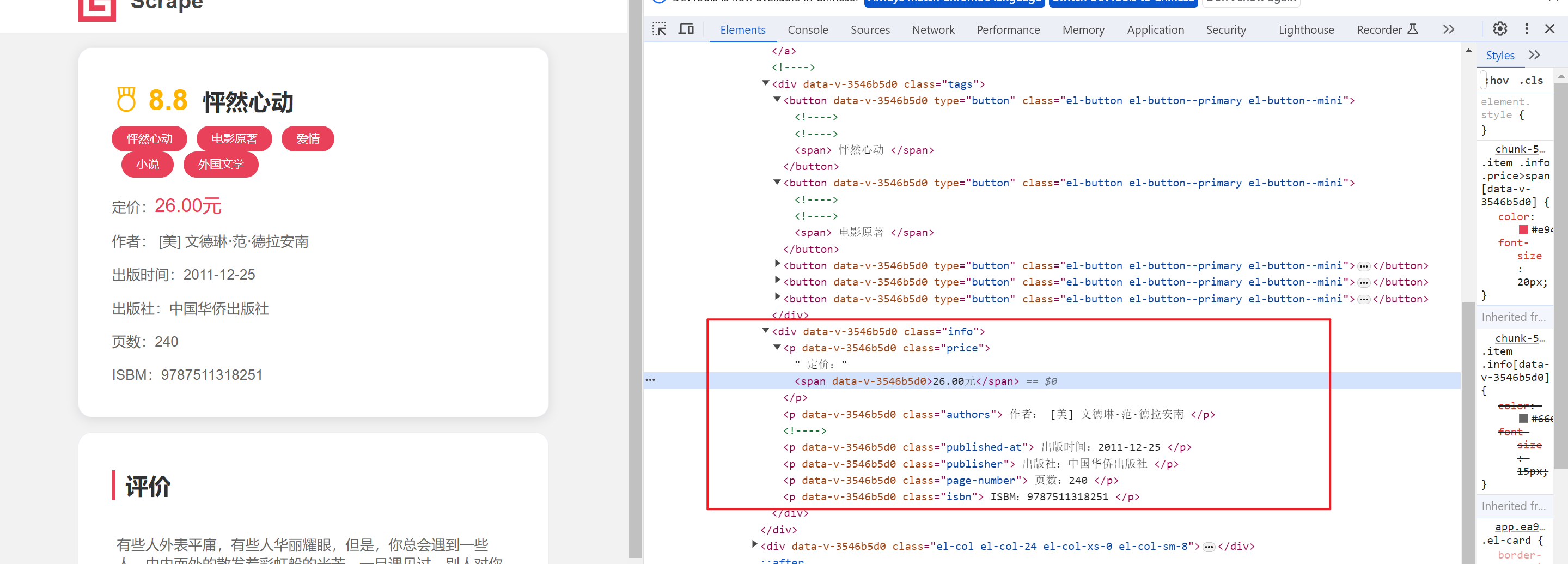
book_price = browser.find_element(by=By.XPATH, value="//p[@class='price']/span").text- 获取作者
这里需要注意一下,标签中的文本有前缀,所以我们要去掉前缀
book_author = browser.find_element(by=By.XPATH, value="//p[@class='authors']").text
book_author = book_author.split("作者:")[1].strip()- 出版时间
book_published_at = browser.find_element(by=By.XPATH, value="//p[@class='published-at']").text
book_published_at = book_published_at.split("出版时间:")[1].strip()- 获取出版社
这里有的图书没有出版社信息,所以为了防止报错,使用异常
try:
book_publisher = browser.find_element(by=By.XPATH, value="//p[@class='publisher']").text
book_publisher = book_publisher.split("出版社:")[1].strip()
except Exception as e:
book_publisher = None- 获取页数
这里有的图书没有页数信息,所以为了防止报错,使用异常
try:
book_page_number = browser.find_element(by=By.XPATH, value="//p[@class='page_number']").text
book_page_number = book_page_number.split("页数:")[1].strip()
except Exception as e:
book_page_number = None- 获取ISBM编号
book_isbn = browser.find_element(by=By.XPATH, value="//p[@class='isbn']").text
book_isbn = book_isbn.split("ISBM:")[1].strip()到这里,数据已经获取结束,我们就可以整合数据了
books_messages.append(
[book_name, book_score, book_tags, book_price, book_author, book_published_at, book_publisher,
book_page_number, book_isbn])然后我们需要返回上一页,继续下一次循环
browser.back()
time.sleep(3)到这里,一个网页中的所有的数据都获取结束,我么就需要进入到下一页中,我们可以定位,下一页的按钮
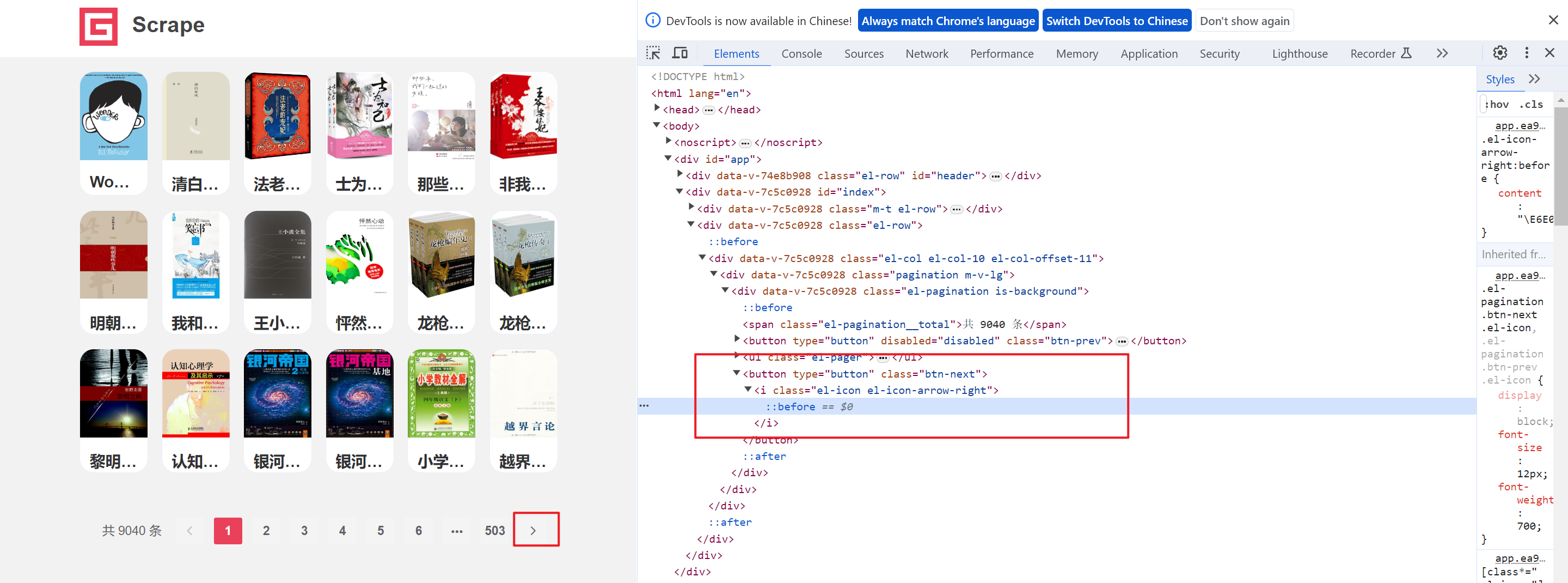
但是当我们采集到最后一页的时候,这个按钮就不能在使用了

所以我们可以使用一个死循环,将上面的代码放在循环中
while True:
....
....
....
# 上面的for循环结束,则表示一页数据获取完毕,则需要继续进行下一页数据的获取
next_btn = browser.find_element(by=By.XPATH, value="//button[@class='btn-next']")
# 标签对象.get_property():获取某个属性的值
if next_btn.get_property("disabled"):
print("数据获取完毕")
break
else:
# 找到下一页的按钮标签,实现点击
next_btn.click()
time.sleep(3)最后在调用保存函数即可
(3) 保存数据:save_data()
这个函数就负责保存数据,在上一个parse_data()函数中,我们最后获得了一个二维数组book_messages,所以我们只需要遍历其中的元素,并且添加到工作表中即可
# 3.保存数据
def save_data(data_list):
for item in data_list:
sheet.append(item)(4)mian代码块
要写入的文件一定要是关闭状态
这里就存放创建和写入文件的一些代码。首先我们要创建一张工作簿,在工作簿被创建的同时会自动创建一张工作表,然后我们获取当前活动的工作表,接着写入表单抬头信息,然后调用get_html函数,最后保存数据到一个路径中即可
if __name__ == '__main__':
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["书名", "评分", "标签", "价格", "作者", "发表时间", "出版商", "页数", "ISBM编号"])
get_data()
wb.save("Scrape图书1-10页.xlsx")c. 完整代码
import time
import openpyxl
from selenium import webdriver
from selenium.webdriver.common.by import By
"""
获取多页的数据
"""
# 1.请求数据
def get_data():
# 创建一个浏览器对象
browser = webdriver.Chrome()
# 设置窗口最大值
browser.maximize_window()
# 打开网页
url = "https://spa5.scrape.center/page/502"
browser.get(url)
# 休眠几秒,渲染页面
time.sleep(3)
# 筛选数据
parse_data(browser)
# 关闭窗口
browser.close()
# 2.获取数据
def parse_data(browser):
books_messages = []
# 要获取多页数据,每一个都是重复下面的操作,所以可以使用死循环解决
while True:
# 获取所有的图书
books_list = browser.find_elements(by=By.XPATH,
value="//div[@class='m-t el-row']/div/div/div")
print(len(books_list))
# 遍历本书书的div
# for循环,获取每一本书的数据
for pos in range(1, len(books_list) + 1):
# 因为需要进入到详情页获取数据,所以点击div
book_div = browser.find_element(by=By.XPATH,
value=f"//div[@class='m-t el-row']/div/div/div[{pos}]")
book_div.click() # 效果相当于鼠标的左键单击
# 休眠几秒,渲染页面
time.sleep(3)
"""开始获取数据"""
# a.获取图书名称
book_name = browser.find_element(by=By.XPATH, value="//h2[@class='m-b-sm name']").text
print(book_name)
# b.获取图书评分
book_score = browser.find_element(by=By.XPATH, value="//span[@class='score m-r']").text
print(book_score)
# c.获取标签,标签位多个
book_tags = browser.find_elements(by=By.XPATH, value="//div[@class='tags']/button")
book_tags = "-".join([tag.text for tag in book_tags])
print(book_tags)
# d.获取定价
book_price = browser.find_element(by=By.XPATH, value="//p[@class='price']/span").text
print(book_price)
# e.获取作者
book_author = browser.find_element(by=By.XPATH, value="//p[@class='authors']").text
book_author = book_author.split("作者:")[1].strip()
print(book_author)
# f.出版时间
book_published_at = browser.find_element(by=By.XPATH, value="//p[@class='published-at']").text
book_published_at = book_published_at.split("出版时间:")[1].strip()
print(book_published_at)
# g.获取出版社,有的图书没有该信息
try:
book_publisher = browser.find_element(by=By.XPATH, value="//p[@class='publisher']").text
book_publisher = book_publisher.split("出版社:")[1].strip()
except Exception as e:
book_publisher = None
print(book_publisher)
# h.获取页数,有的图书没有该信息
try:
book_page_number = browser.find_element(by=By.XPATH, value="//p[@class='page_number']").text
book_page_number = book_page_number.split("页数:")[1].strip()
except Exception as e:
book_page_number = None
print(book_page_number)
# i.获取ISBM编号
book_isbn = browser.find_element(by=By.XPATH, value="//p[@class='isbn']").text
book_isbn = book_isbn.split("ISBM:")[1].strip()
print(book_isbn)
# 整合数据
books_messages.append(
[book_name, book_score, book_tags, book_price, book_author, book_published_at, book_publisher,
book_page_number, book_isbn])
# 返回到上一页
browser.back()
time.sleep(3)
# 上面的for循环结束,则表示一页数据获取完毕,则需要继续进行下一页数据的获取
next_btn = browser.find_element(by=By.XPATH, value="//button[@class='btn-next']")
# 标签对象.get_property():获取某个属性的值
if next_btn.get_property("disabled"):
print("数据获取完毕")
break
else:
# 找到下一页的按钮标签,实现点击
next_btn.click()
time.sleep(3)
# 写入数据
save_data(books_messages)
# 3.保存数据
def save_data(data_list):
for item in data_list:
sheet.append(item)
if __name__ == '__main__':
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["书名", "评分", "标签"])
get_data()
wb.save("Scrape图书数据.xlsx")




暂无评论内容