一、BS4解析中国新闻网
1.1 需求
抓取中国新闻网及时新闻页面的内容,主要抓取”新闻类别“、”新闻标题“、”新闻时间“以及”新闻链接“,并且整理成
[['图片', '瑞士选手获女子自由式滑雪大跳台世界杯冠军', 'https://www.chinanews.com//tp/hd2011/2023/12-02/1088877.shtml', '12-2 17:20'],,...的格式,然后保存到csv文件中
网站地址:https://www.chinanews.com/scroll-news/news1.html
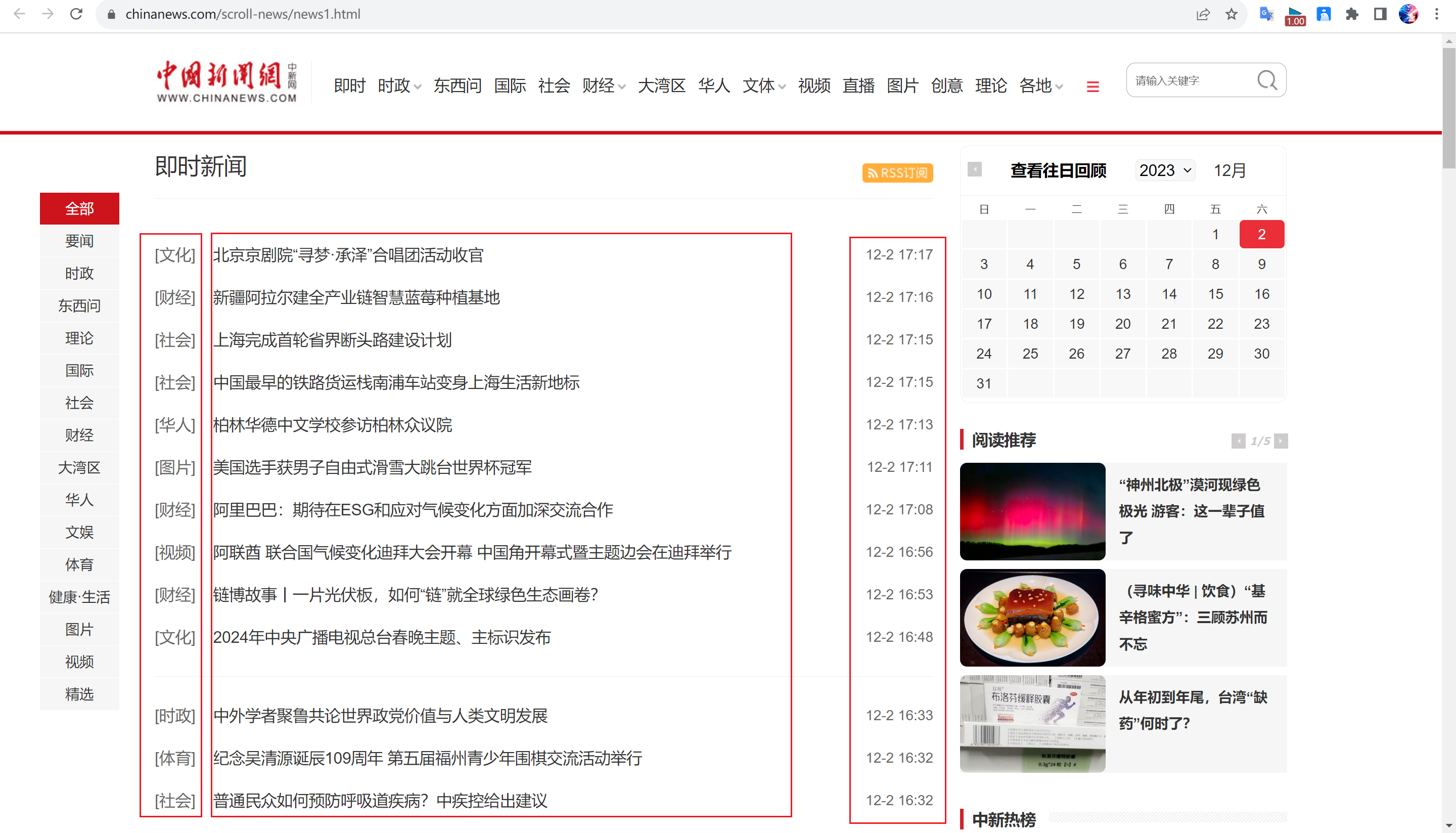
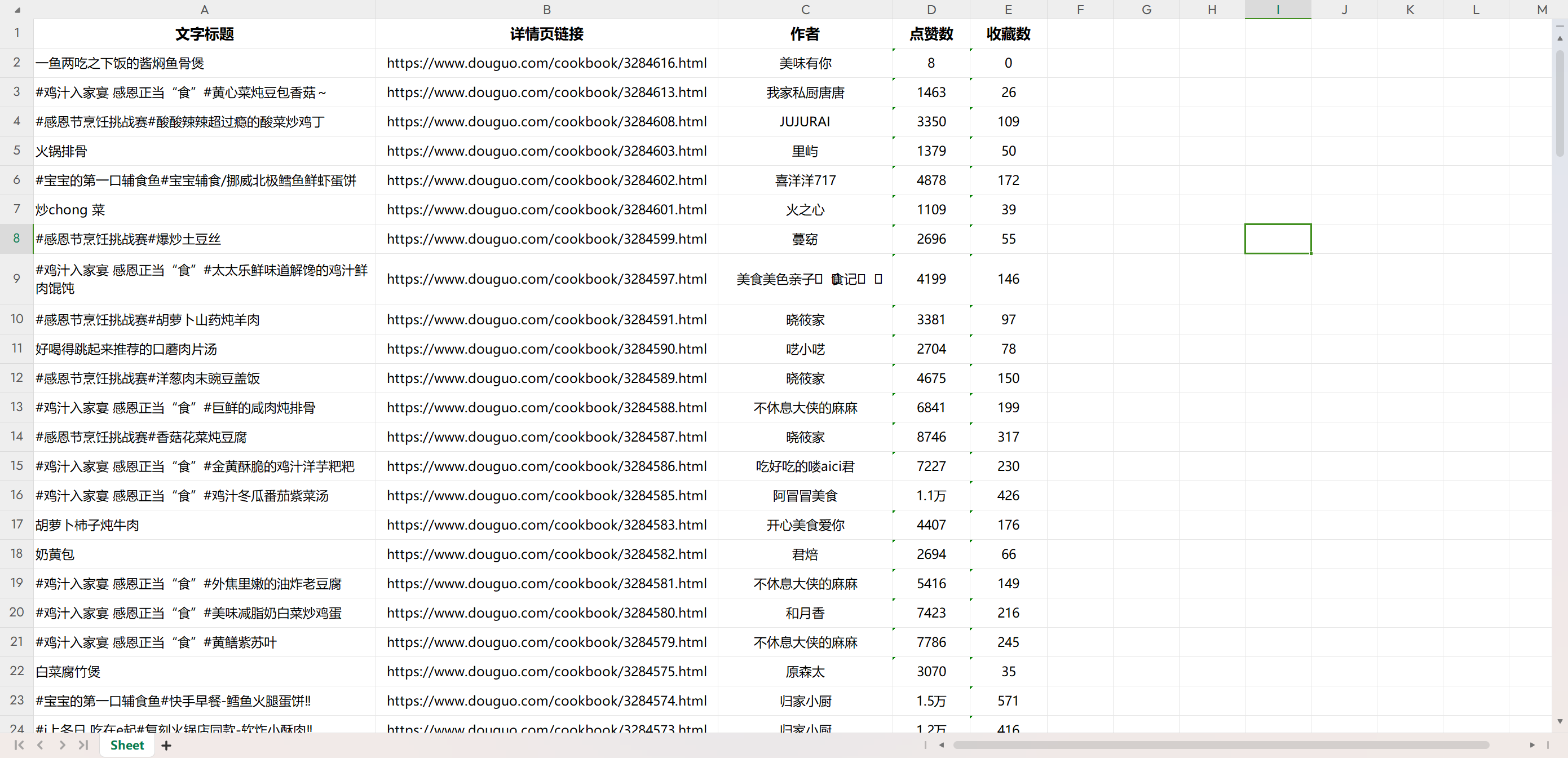
1.2 结果展示
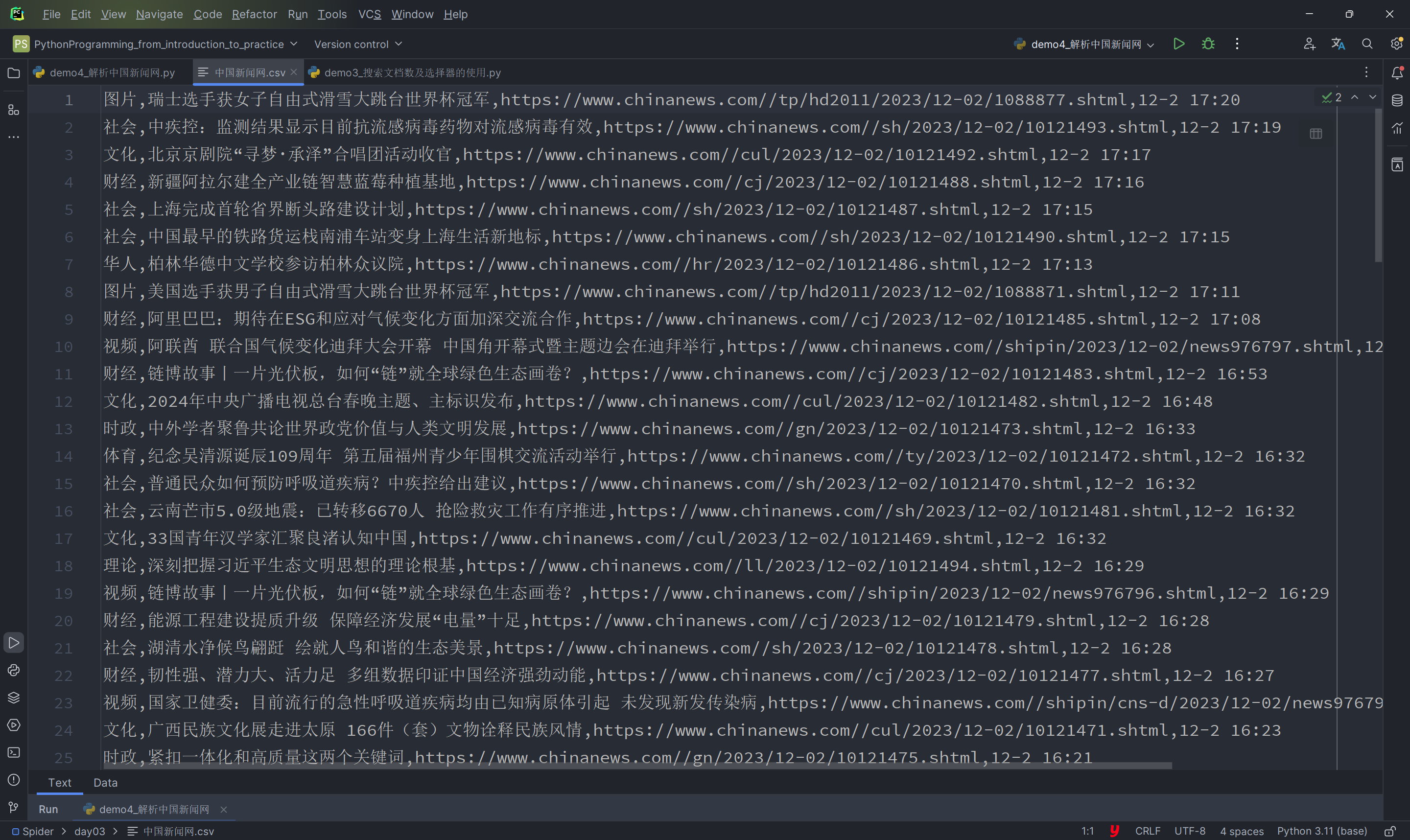
1.3 分析
提取网站数据,所以需要用到requests模块,提取指定项内容,需要用bs4,从而需要bs4模块,最后保存csv文件,需要用到csv模块,所以我们需要用到上述的三个模块
import requests, csv
from bs4 import BeautifulSoup然后我们可以定义三个函数,分别用于获取整个网页数据:get_data():,提取需要的数据:parser_data():,保存到csv文件:save_data():
1.3.1 get_data():
get_data():函数,主要用于获取整个网页数据,URL,需求中已经给出,所以可以直接定义:
url = "https://www.chinanews.com/scroll-news/news1.html"headers可以根据浏览器打开网页,F12查看网页资源,在请求头中有一个参数User-Agent:作用是表标识浏览器的相关信息,足以处理大多数的网站,即
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}需要注意的是,书写的时候一定要写成key:value的形式,即给两部分内容加上引号
然后就可以获取网页资源了
resp = requests.get(url, headers=headers)为了优化代码,可以加一个判断,如果状态码正确,则打印内容,然后调用parser_data():函数,提取需要的信息,否则则报错。如果能够抓取,但是中文显示有问题的话,还需要设置编码,即
if resp.status_code == 200:
print("请求成功")
resp.encoding = 'utf-8'
print(resp.text)
parser_data(resp.text)
else:
print(f"抓取失败,状态码:{resp.status_code}")1.3.2 parser_data():
parser_data():函数用于提取有效信息,配合F12检查界面,我们可以很清晰的定位到,需要的内容所在的位置和格式。
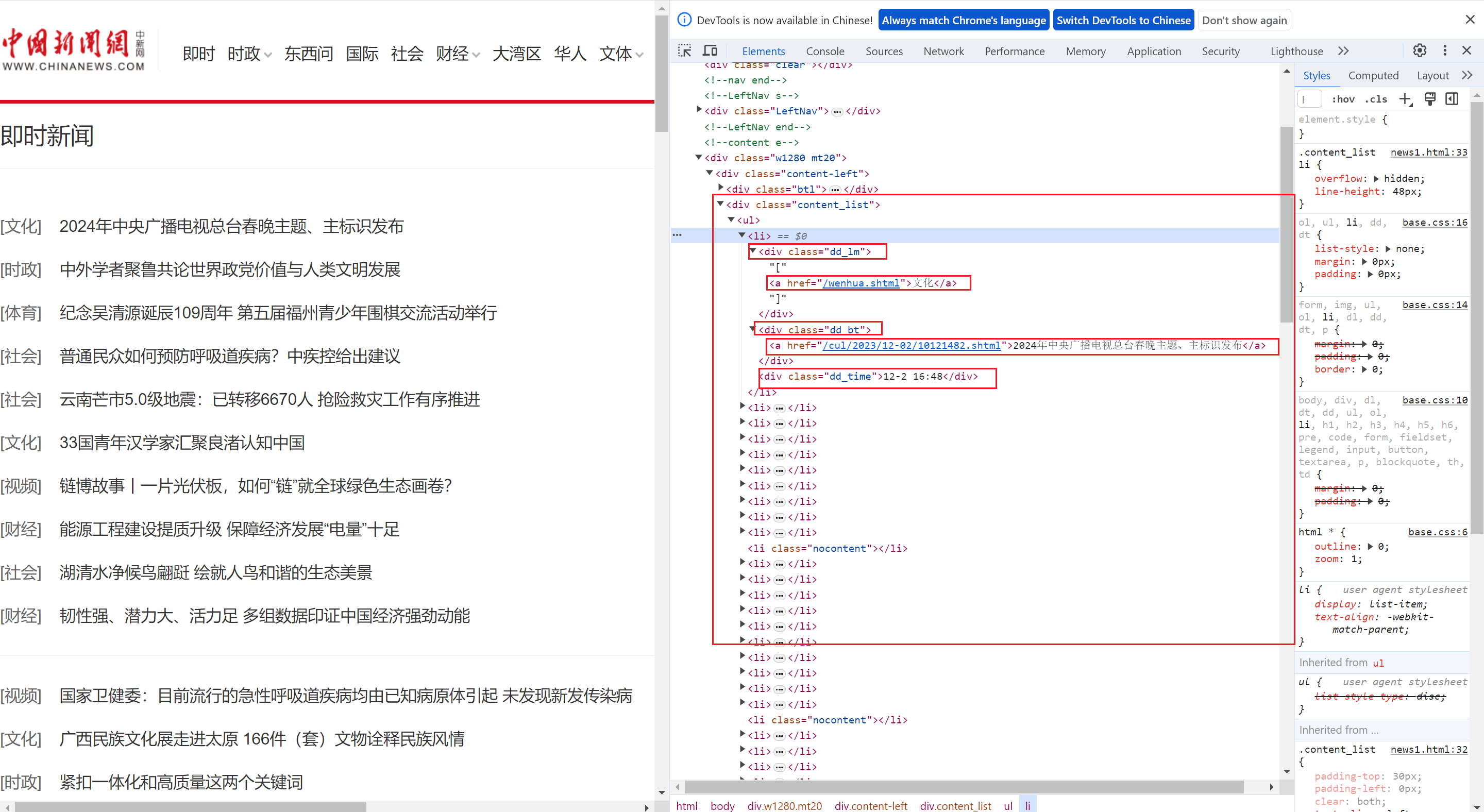
我们使用bs4来进行解析,所以首先需要创建bs4对象,并制定解析器
soup = BeautifulSoup(data, 'html.parser')可以搭线所需要的内容格式都很同意,都在li标签中,所以我们先提取需要的所有li标签
# 获取所有表示新闻的li标签
li_list = soup.select('div.content_list li')
print(li_list)然后,获取到的li中,有的部分是无效的,对应图中的横线,所以我们要判断选择,然后再调用select_one方法提取内容,需要注意的是,链接在标签中是没有前缀的,所以我们还需要给链接添加前缀,最后把这些内容整个到一个列表中,即最终的列表为二维列表
data_list = []
# 单独提取每一条新闻
for li in li_list:
if li.select_one('.dd_lm > a') is not None:
# 新闻类型
news_type = li.select_one('.dd_lm > a').text
# print(news_type)
# 新闻标题
news_title = li.select_one('.dd_bt > a').text
# print(news_title)
# 新闻时间
news_time = li.select_one('.dd_time').text
# print(news_time)
# 新闻链接
news_link = 'https://www.chinanews.com/' + li.select_one('.dd_bt > a').attrs['href']
print(news_link)
# 数据整合,二维数组
data_list.append([news_type, news_title, news_link, news_time])至此,提取部分完成,下面就是调用save_data()函数,将数据保存
1.3.3 save_data()
save_data()函数,复制将列表中的数据保存到csv文件中,采用with表达式即可
def save_data(data):
with open(f'中国新闻网.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)
print('保存成功')xxxxxxxxxx def save_data(data): with open(f'中国新闻网.csv', 'w', encoding='utf-8', newline='') as f: writer = csv.writer(f) writer.writerows(data) print('保存成功')with open(r"猫眼电影.csv", 'w', encoding='utf-8', newline='') as f: writer = csv.writer(f) writer.writerows(data)1.4 完整代码
# -*- coding: utf-8 -*-
# @Time : 2023/12/2 16:45
# @Author : Eden Wei
# @FileName: demo4_解析中国新闻网.py
# @Software: PyCharm 2023.2.4 (Professional Edition)
import requests, csv
from bs4 import BeautifulSoup
# 1.获取数据
def get_data():
url = "https://www.chinanews.com/scroll-news/news1.html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
print("请求成功")
resp.encoding = 'utf-8'
print(resp.text)
parser_data(resp.text)
else:
print(f"抓取失败,状态码:{resp.status_code}")
# 2.解析数据
def parser_data(data):
soup = BeautifulSoup(data, 'html.parser')
# 获取所有表示新闻的li标签
li_list = soup.select('div.content_list li')
print(li_list)
data_list = []
# 单独提取每一条新闻
for li in li_list:
if li.select_one('.dd_lm > a') is not None:
# 新闻类型
news_type = li.select_one('.dd_lm > a').text
# print(news_type)
# 新闻标题
news_title = li.select_one('.dd_bt > a').text
# print(news_title)
# 新闻时间
news_time = li.select_one('.dd_time').text
# print(news_time)
# 新闻链接
news_link = 'https://www.chinanews.com/' + li.select_one('.dd_bt > a').attrs['href']
print(news_link)
# 数据整合,二维数组
data_list.append([news_type, news_title, news_link, news_time])
print(data_list)
save_data(data_list)
# 3.存储数据
def save_data(data):
with open(f'中国新闻网.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)
print('保存成功')
if __name__ == '__main__':
get_data()二、BS4解析中国新闻网1-10页内容,并且数据持久化
# -*- coding: utf-8 -*-
# @Time : 2023/12/3 18:24
# @Author : Eden Wei
# @FileName: demo4_翻页爬取数据_中国新闻网.py
# @Software: PyCharm 2023.2.4 (Professional Edition)
"""
获取中文新闻网,1-10页的内容
并且数据持久化
"""
import time
import random
import openpyxl
import requests
from bs4 import BeautifulSoup
# 1.获取数据
def get_data():
for i in range(1, 11):
url = f"https://www.chinanews.com/scroll-news/news{i}.html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
# 设置时间间隔,防止被检测为攻击,sleep()函数单位为秒
time.sleep(random.randint(3, 6))
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
print("请求成功")
resp.encoding = 'utf-8'
# print(resp.text)
parser_data(resp.text)
else:
print(f"抓取失败,状态码:{resp.status_code}")
# 2.解析数据
def parser_data(data):
soup = BeautifulSoup(data, 'html.parser')
# 获取所有表示新闻的li标签
li_list = soup.select('div.content_list li')
print(li_list)
data_list = []
# 单独提取每一条新闻
for li in li_list:
if li.select_one('.dd_lm > a') is not None:
# 新闻类型
news_type = li.select_one('.dd_lm > a').text
# print(news_type)
# 新闻标题
news_title = li.select_one('.dd_bt > a').text
# print(news_title)
# 新闻时间
news_time = li.select_one('.dd_time').text
# print(news_time)
# 新闻链接
news_link = 'https://www.chinanews.com/' + li.select_one('.dd_bt > a').attrs['href']
print(news_link)
# 数据整合,二维数组
data_list.append([news_type, news_title, news_link, news_time])
print(data_list)
save_data(data_list)
# 3.存储数据
def save_data(data_list):
for data in data_list:
sheet.append(data)
if __name__ == '__main__':
# 创建工作簿,创建工作簿的同时会创建一张工作表
wb = openpyxl.Workbook()
# 确定工作表
sheet = wb.active
sheet.append(["类型", "标题", "链接", "时间"])
get_data()
wb.save("中国新闻网.xlsx")







暂无评论内容