最新发布第2页

Selenium的进阶使用(二)
二、Selenium进阶使用 2.1 窗口的切换 2.1.1 切换到显式窗口 显式窗口:顾名思义,通过按钮的点击,可以直接打开一个新的窗口 前面提到点击事件click(),是在原窗口中更改网页,所以放打开一个...
Selenium的进阶使用(一)
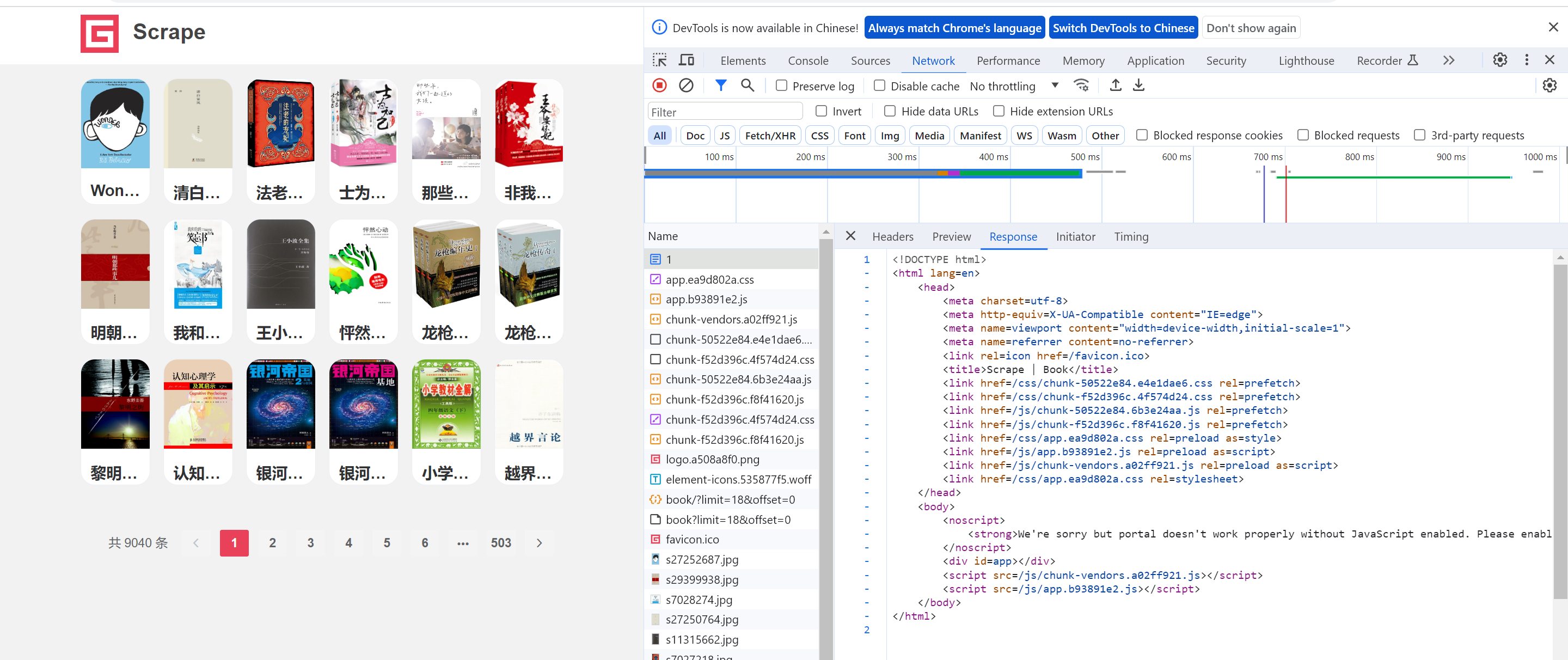
一、Selenium进阶使用 1.1 Selenium获取Scrape图书信息 需求:使用Selenium请求Scrape图书网站1-10页,使用bs4或xpath解析数据 获取"书名", "评分", "标签", &qu...
Spider练习(三):Selenium提取LOL英雄数据
一、需求 使用Selenium提取数据,从英雄联盟首页进入 https://lol.qq.com/main.shtml 点击英雄资料 ,进入到英雄列表,然后保存 "英雄名称", "英雄职业", "英雄技能&q...
Selenium解析实战:解析scrape图书
一、Selenium获取Scrape图书信息 1.1 需求 需求:使用Selenium请求Scrape图书网站1-10页,使用bs4或xpath解析数据 获取"书名", "评分", "标签", "价格"...
自动化测试工具Selenium
一、Selenium Selenium 是一个用于 web程序的自动化测试工具,直接运行在浏览器中,能够像真正的用户一样操作浏览器,也就是说,利用它可以驱动浏览器执行特定的行为,最终帮助爬虫开发者获...

Requests请求动态数据
一、静态页面和动态页面 通俗来讲: 静态网页:网页的内容一经发布,除非再进行人为的修改,否则页面内容不会发生改变。 动态页面:虽然同样页面代码不发生变化,但是其显示的内容确实可以随着...
XPATH解析实战(二):豆果美食菜谱
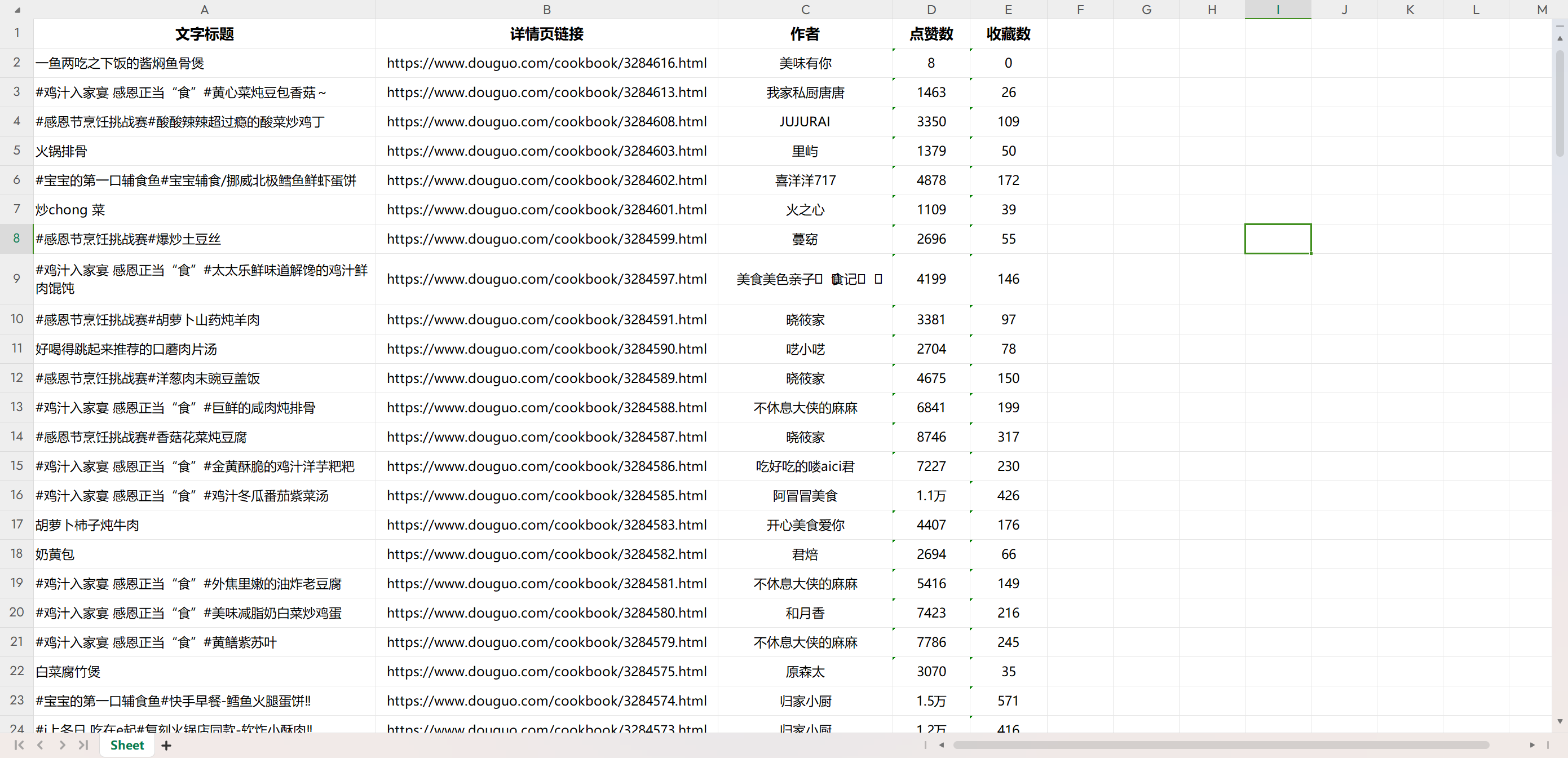
一、需求 解析豆果美食的数据,保存"文章标题", "详情页链接", "作者", "点赞数", "收藏数"等信息,并实现数据持久化,保存到excel文件中 ...

XPATH解析实战(一):解析Scrape电影网数据
一、需求 解析Scrape电影网的数据,保存"电影名称", "电影类型", "国家", "时间", "评分", "上映时间"等信息,并实现数据持久化...
XPATH路径提取规则
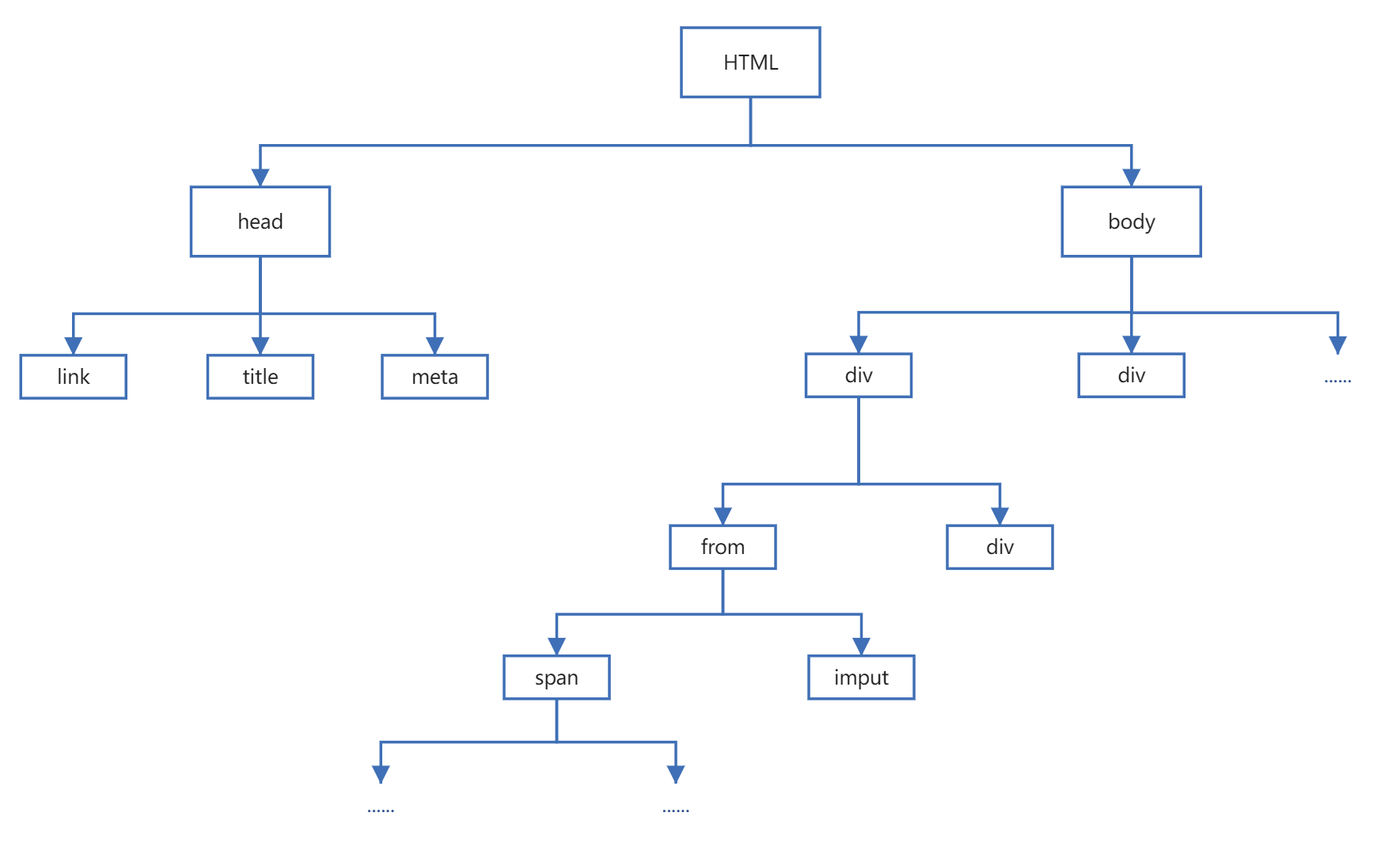
一、XPATH 前面的学习中,学习了正则表达式解析,但是正则解析能用,但是相对比较麻烦;所有又学习了BS4解析,这是一个常用的方式,需要重点掌握,并且着重关注select和select_one以及配合使用c...
Spider练习(二):使用BS4抓取豆瓣电影T250
一、需求 使用BS4提取豆瓣电影Top250,1-10页的电影数据,包括'电影名称', '详情页地址', '上映年份','国家','类型', '评分','评论人数',并将结果保存到Excel文件中 网址:https://movie.douba...




