一、Selenium
Selenium 是一个用于 web程序的自动化测试工具,直接运行在浏览器中,能够像真正的用户一样操作浏览器,也就是说,利用它可以驱动浏览器执行特定的行为,最终帮助爬虫开发者获取到网页的动态内容
简单的说,只要我们在浏览器窗口中能够看到的内容,都可以使用 Selenium 获取到,对于那些使用 JavaScript 动态渲染技术的网站,Selenium 会是一个重要的选择。
支持IE浏览器、谷歌浏览器、Edge、火狐浏览器、Safari浏览器、欧鹏浏览器等。但是建议使用谷歌浏览器,因为谷歌为Selenium适配了一个CDP(谷歌开发者工具协议)的协议,Selenium结合CDP能够发挥出巨大的威力
1.1 环境配置
以 Chrome 浏览器为例
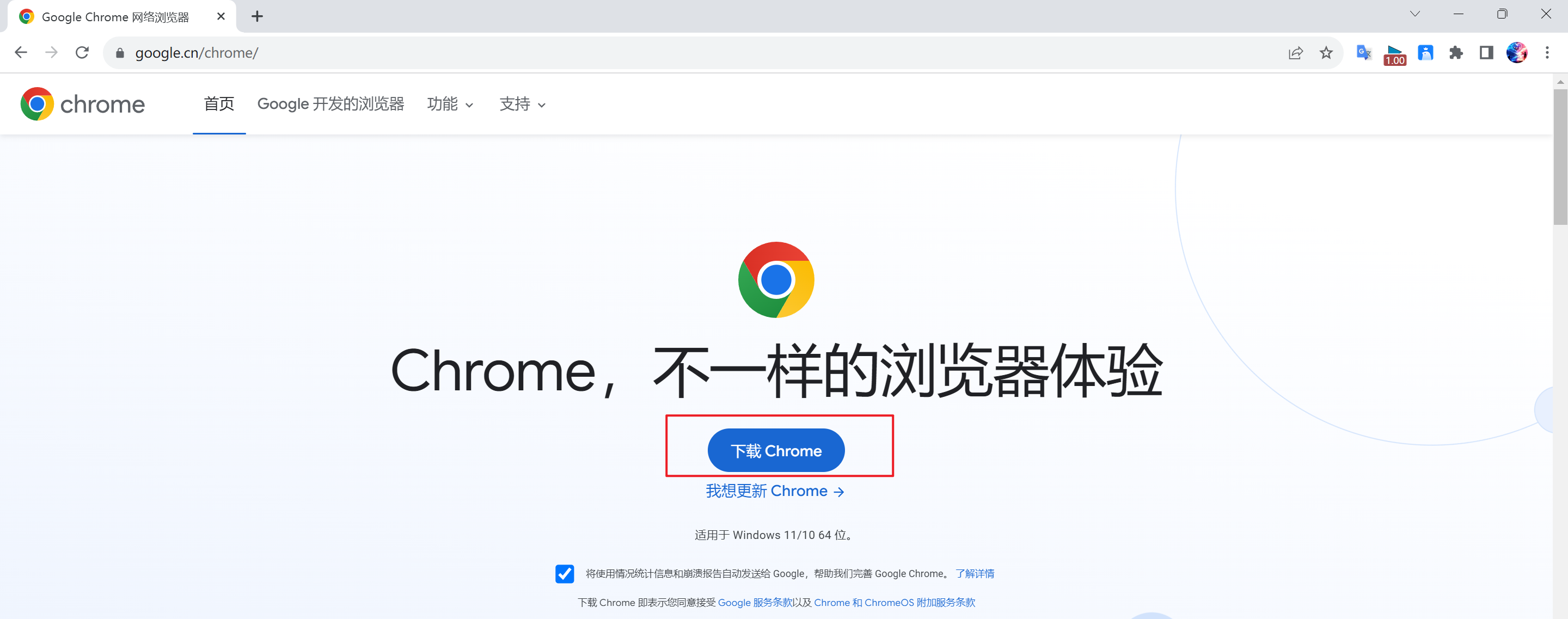
- 安装Chrome浏览器
官方网址:https://www.google.cn/chrome/
-
确定版本
- 方式一:右上角 ——> 设置 ——> 于Chrome
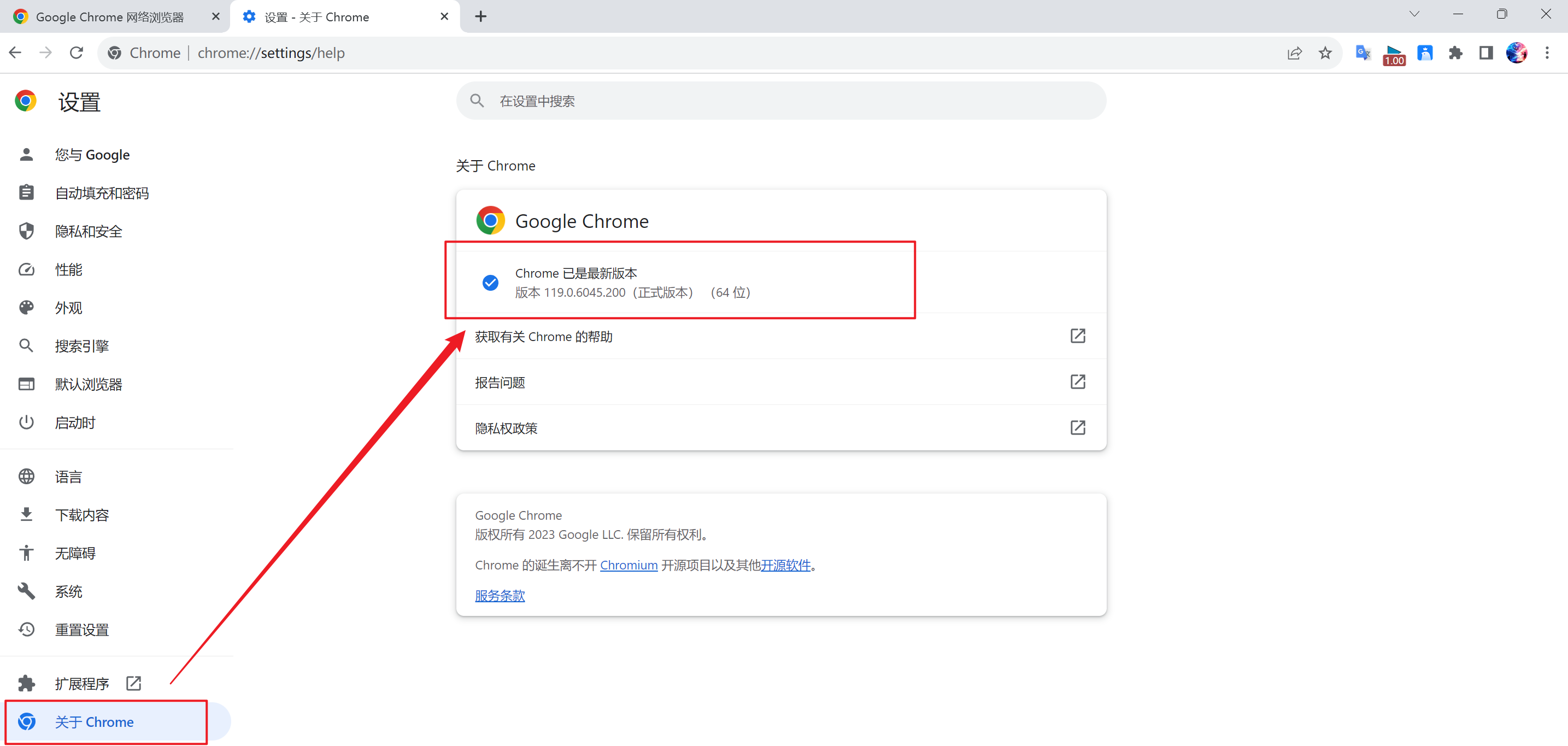
- 方式二:浏览器地址栏出搜索:
chrome://version/
-
安装selenium
pip install selenium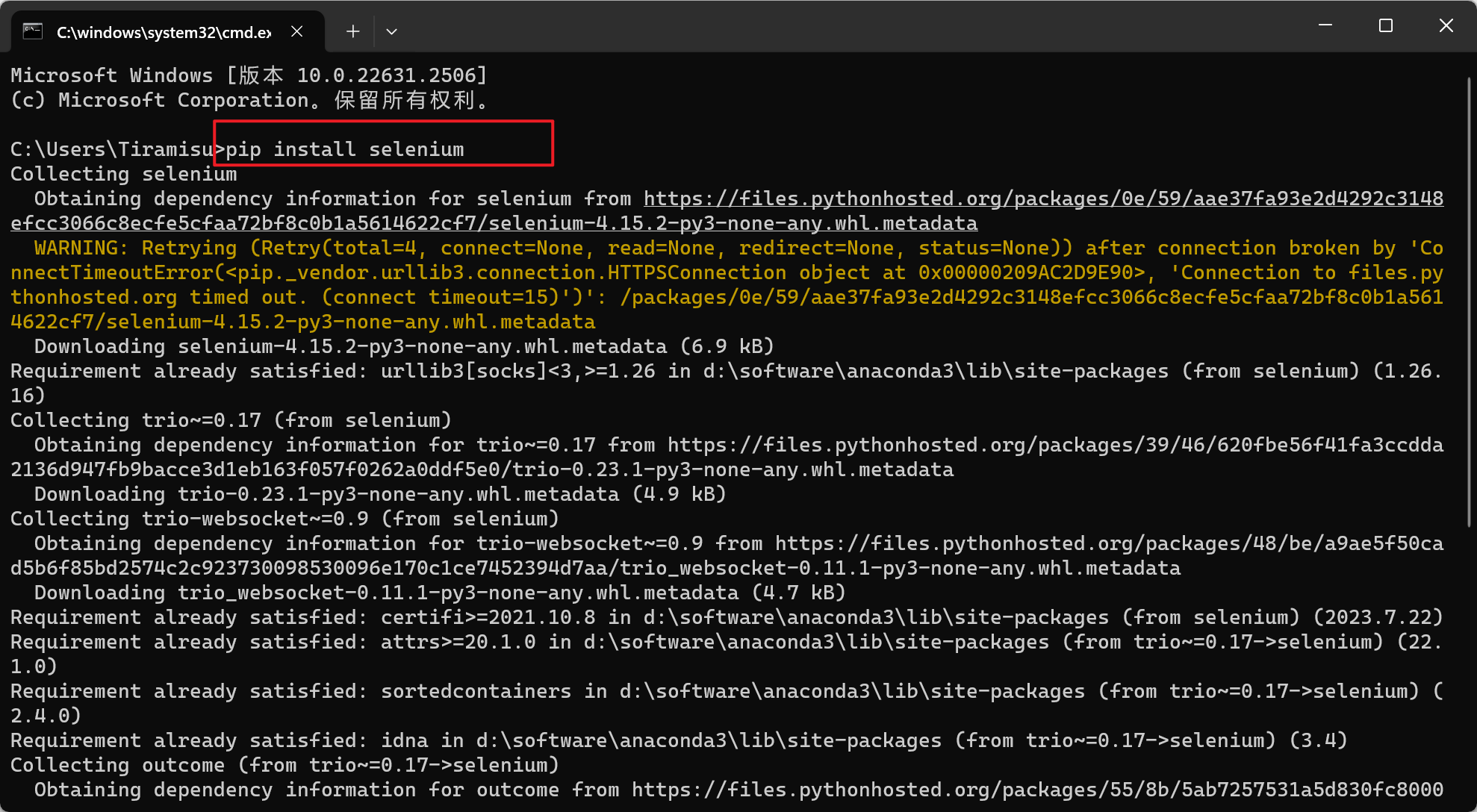
1.2 测试环境是否成功
测试代码
from selenium import webdriver
import time
# 创建一个Chrome浏览器实例对象
# 注意:如果要使用其他浏览器,可以使用其他对应的类,如:Edge()等
brower = webdriver.Chrome()
# 设置浏览器的尺寸,使得最大化
brower.maximize_window()
# 加载执行的网页
brower.get("https://www.baidu.com") # 等价于 requests.get()
# 获取源代码
print(brower.page_source) # 等价于 resp.text
# 休眠,稍作停留,等待HTML页面完成渲染
time.sleep(10)
# 浏览器使用完毕,手动关闭
brower.close()1.3 可能出现的问题
如果上述代码运行报错
selenium.common.exceptions.WebDriverException:Message:'chromedriver'executableneedsto be in
PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home解决方案
-
1.要求有个谷歌浏览器
-
2.查看已安装的谷歌浏览器的版本号
-
3.下载驱动文件
- https://registry.npmmirror.com/binary.html?path=chromedriver/
- 或者https://npm.taobao.org/mirrors/chromedriver/
- 但是,如果浏览器版本过高,可以通过https://googlechromelabs.github.io/chrome-for-testing/下载
- 根据已安装的浏览器的版本号寻找相匹配的文件夹,如果没有,找最相近的但是低于已安装浏览器版本号的文件夹。
-
下载的驱动压缩包解压
- 解压完:windows系统能看到一个chromedriver.exe的文件
- mac能看到一个chromedriver的文件
-
将chromedriver.exe放到当前工程根目录下
-
安装selenium模块
- windows:
pip install selenium - mac、linux:
pip3 install selenium
- windows:
-
验证环境是否OK
# mac系统写法: driver = Chrome(service=Service(executable_path='./chromedriver')) # windows系统: # driver = Chrome(service=Service(executable_path='./chromedriver.exe')) driver.get(url='https://www.baidu.com/') driver.close()
1.4 应用
1.4.1 Selenium驱动百度搜索关键字
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# 创建Chrome浏览器对象
brower = webdriver.Chrome()
# 设置浏览器窗口最大化
brower.maximize_window()
# 请求百度网站
brower.get("https://www.baidu.com/")
# 休眠一点时间,渲染HTML网页
time.sleep(3)
# 定位到指定标签
"""
# 注意:使用selenium定位元素,不管使用bs4还是xpath,都只能定位到标签,不能定位到文本
find_element(by,value):
find_elements(by,value):
by:
ID:id,通过标签的id属性值进行查找
XPATH:表示根据xpath路径规则进行定位
CSS_SELECTOR:根据css选择器进行定位
LINK_TEXT:通过a标签的内容获取标签(只针对a标签)
value:方式对应的值
"""
# 导包的快捷键,ctrl + enter ,快速导包
kw_input = brower.find_element(by=By.ID, value='kw')
# 要想向输入框中传入数据
kw_input.send_keys("Python")
# 传递回车键,结束输入,进行搜索
kw_input.send_keys(Keys.ENTER)
time.sleep(10)
brower.close()1.4.2 Selenium驱动酷狗下载音乐
import os.path
import time
import requests
from selenium import webdriver
from bs4 import BeautifulSoup
# 1.获取数据
def get_music_url():
url = "https://www.kugou.com/yy/rank/home/1-52144.html?from=rank"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/119.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers=headers)
# print(resp.text)
soup = BeautifulSoup(resp.text, 'html.parser')
a_list = soup.select('.pc_temp_songname')
# 通过request请求,结果不对
# music_url = "https://www.kugou.com/mixsong/9c2z3wf8.html"
# music_resp = requests.get(music_url, headers=headers)
# print(music_resp.text)
# 使用selenium请求
# 创建浏览器对象
driver = webdriver.Chrome()
for a in a_list:
driver.get(a.attrs["href"])
# 程序休眠,渲染HTML页面
# time.sleep(3)
# 获取页面源代码
data = driver.page_source
# 对详情页进行解析
music_soup = BeautifulSoup(data, "html.parser")
# 获取音乐文件的URL
music_url = music_soup.select_one("#myAudio").attrs["src"]
print(music_url)
# 获取音乐的名称
music_name = music_soup.select_one("#songNameTemp").attrs['title']
print(music_name)
# 下载文件
res = requests.get(music_url)
# 判断是否需要创建文件夹
if not os.path.exists("music"):
os.mkdir("music")
# 写入文件,音乐在Python中属于二进制文件
with open(fr"music/{music_name}.mp3", "wb") as f:
f.write(res.content)
print(f"{music_name}下载完成")
if __name__ == '__main__':
get_music_url()THE END







暂无评论内容