一、XPATH
前面的学习中,学习了正则表达式解析,但是正则解析能用,但是相对比较麻烦;所有又学习了BS4解析,这是一个常用的方式,需要重点掌握,并且着重关注select和select_one以及配合使用css选择器。
下面学习第三种方式解析:XPath解析
1.1 概念介绍
XPath,全称 XML Path Language,即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。跟BeautifulSoup4一样都是用来解析页面内容的工具,只不过使用方式有所不同而已
xml是一种标记语法的文本格式,xpath可以方便的定位xml中的元素和其中的属性值。lxml是python中的一个第三方模块,它包含了将html文本转成xml对象,和对xml对象执行xpath的功能
使用 XPath 解析数据,需要安装 lxml 库
pip install lxml1.1.1 HTML树型结构
HTML 的结构就是树形结构,HTML 是根节点,所有的其他元素节点都是从根节点发出的。其他的元素都是这棵树上的节点Node,每个节点还可能有属性和文本。而路径就是指某个节点到另一个节点的路线。 而我们使用xpath就是根据这些路线所确定的
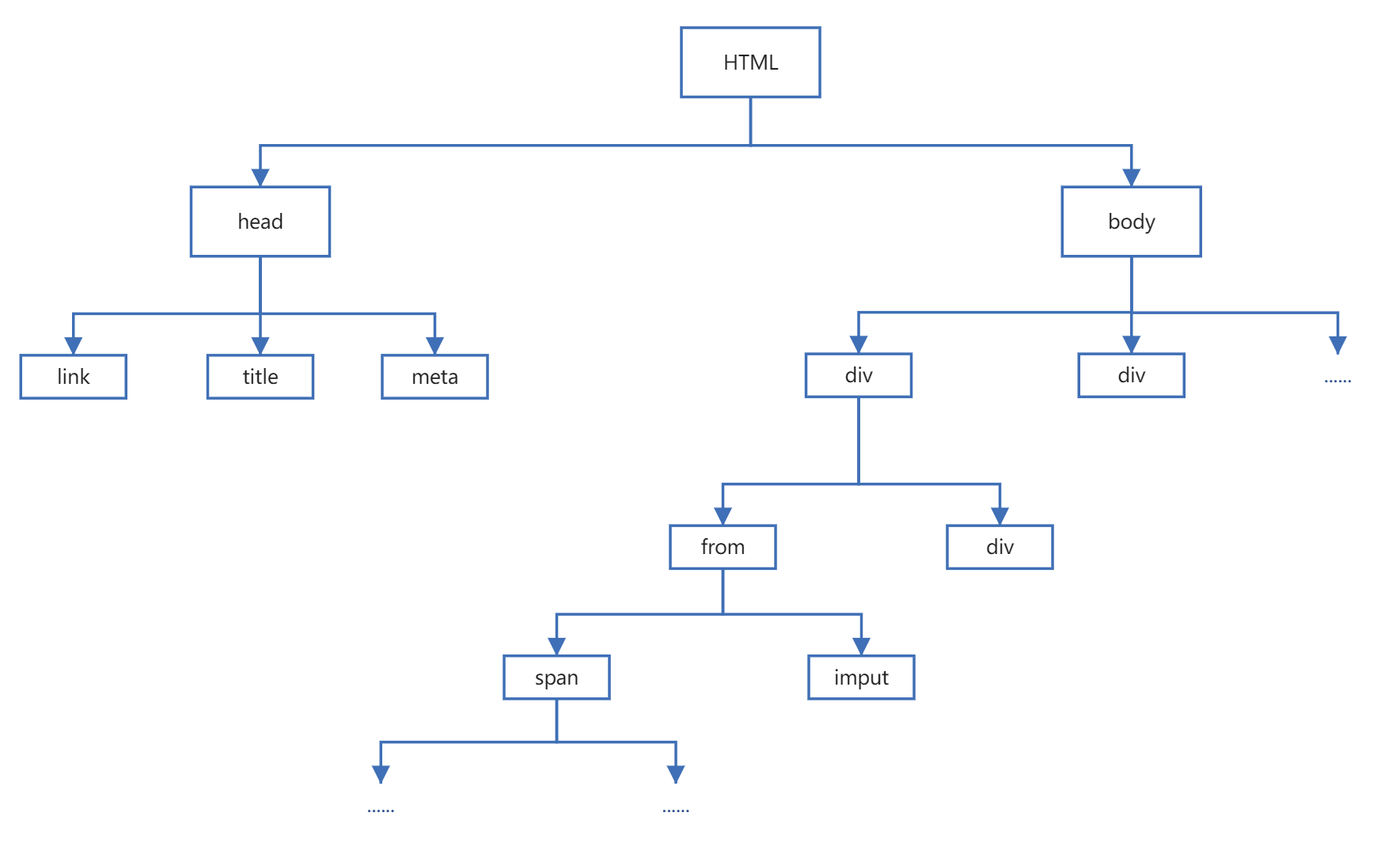
上述HTML 树型结构图中,节点之间的关系如下:
- 父节点(Parent): HTML 是 body 和 head 节点的父节点
- 子节点(Child):head 和 body 是 HTML 的子节点
- 兄弟节点(Sibling):拥有相同的父节点,head 和 body 就是兄弟节点。title 和 div 不是兄弟,因为他们不是同一个父节点
- 祖先节点(Ancestor):body 是 form 的祖先节点,爷爷辈及以上
- 后代节点(Descendant):form 是 HTML 的后代节点,孙子辈及以下
1.1.2 绝对路径和相对路径
-
文件的相对路径和绝对路径:
以books.xml文件为例
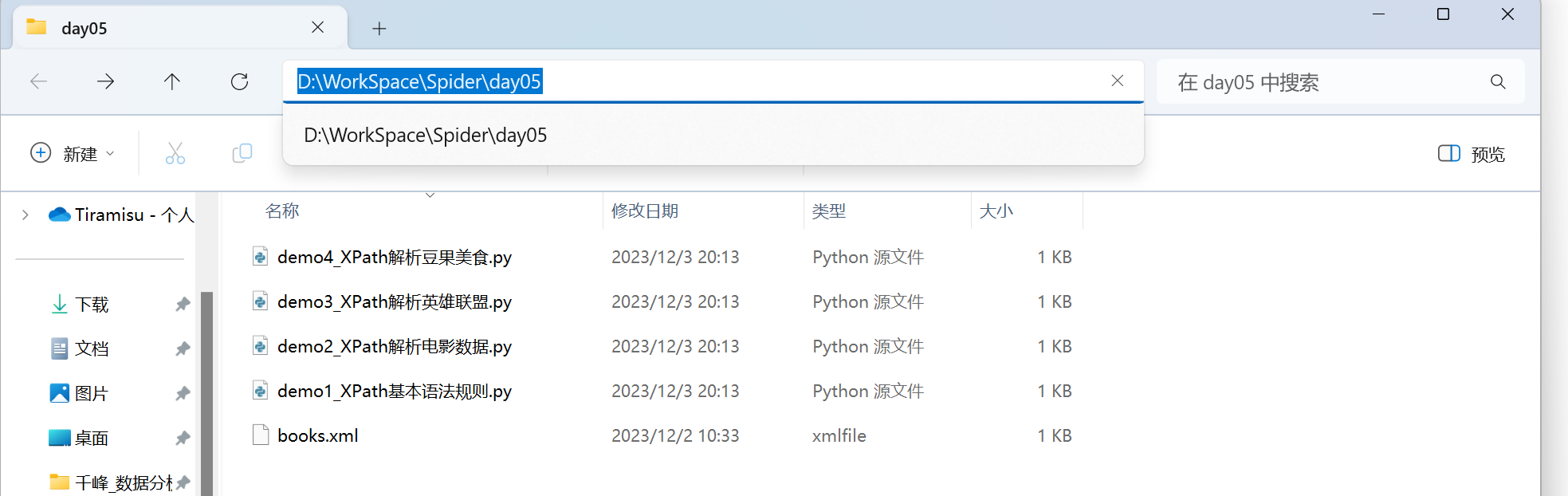
- 绝对路径:
D:\WorkSpace\Spider\day05\books.xml - 相对路径:
books.xml
- 绝对路径:
在标签中
-
绝对路径:从HTML根节点开始算,一步一步根据标签的嵌套关系书写出来的路径
-
相对路径:从任意节点开始算,以
//(相当于全局搜索)开头,相对路径可以从任意节点开始,一般我们会选取有id属性或class属性的标签开始书写,可以增加查找的准确性,推荐相对路径
如何找到一个标签的路径,以百度首页的 logo 为例
- 第一步:定位到图片的标签
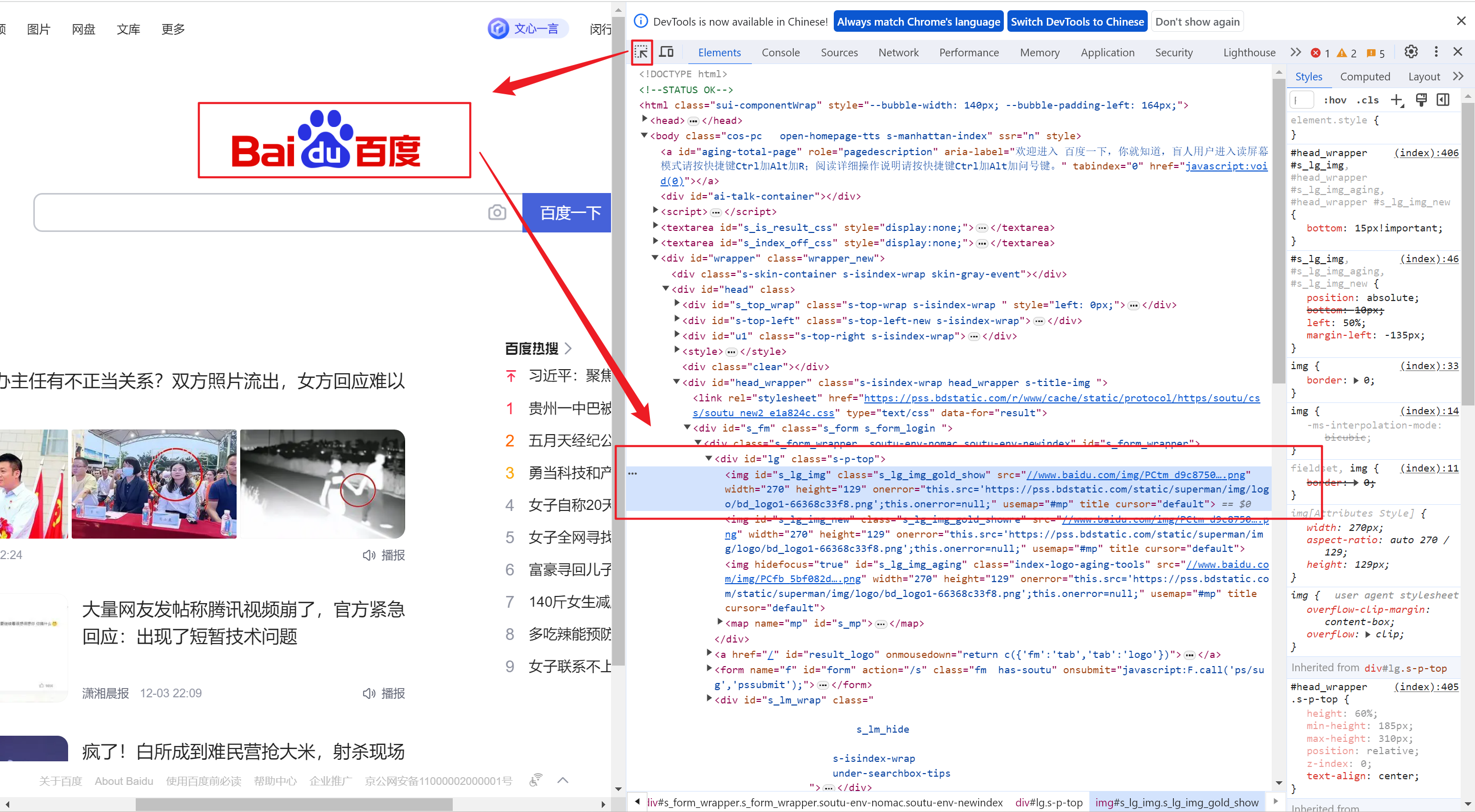
- 第二步:右键 ——> Copy ——> opy XPath或Copy full XPath
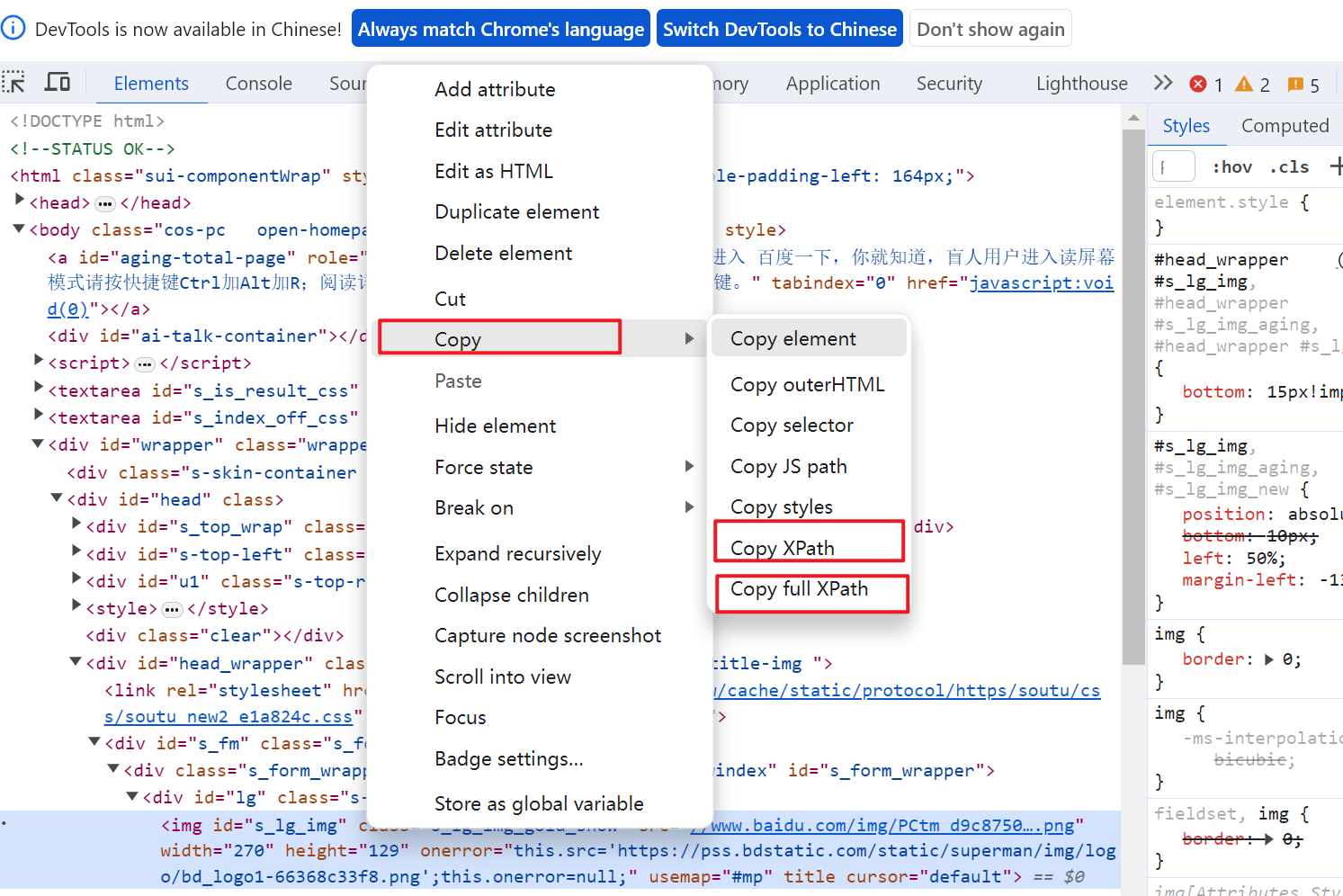
Copy XPath:相对路径
//*[@id="result_logo"]/img[1]Copy full XPath:绝对路径
/html/body/div[2]/div[2]/div[5]/div[1]/div/a/img[1]但是由于拷贝出来的代码缺乏灵活性,也不全然准确。大部分情况下,都需要自己定义 Xpath 语句,因此 Xpath 语法还是有必要学习
1.2 相对路径定位语法
1.2.1 基本语法
基本定位语法:
| 表达式 | 说明 | 举例 |
|---|---|---|
| / | 从根节点开始选取 | /html/div/span |
| // | 从任意节点开始选取 | //input//img//div//div/p/a |
| . | 选取当前节点 | ./p和/p的区别:./p表示从当前节点开始查找/p表示从根节点开始查找 |
| .. | 选取当前节点的父节点 | //input/.. 会选取 input 的父节点 |
| @ | 选取属性或者根据属性选取 | //input[@data]选取具备 data 属性的 input 元素 //@data 选取所有 data 属性 |
| * | 通配符,表示任意节点或任意属性 |
元素属性定位:
- 属性定位是通过
@符号指定需要使用的属性
使用谓语定位:
- 谓语是 Xpath 中用于描述元素位置。主要有数字下标、最后一个子元素last()、元素下标函数position()。
- 注意:Xpath 中的下标从
1开始
- 注意:Xpath 中的下标从
使用逻辑运算符定位
- 如果元素的某个属性无法精确定位到这个元素,我们还可以用逻辑运算符
and连接多个属性进行定位 - 常用的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| or | 或 | age = 18 or age = 20 | age = 18 : True; age = 21 : False |
| and | 与 | age > 18 and age < 21 | age = 20 : True; age = 21 : False |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
| | | 计算两个节点集 | //book | //cd | 返回所有拥有book和cd元素的节点集 |
| + | 加法 | 5 + 3 | 8 |
| - | 减法 | 5 - 3 | 2 |
| * | 乘法 | 5 * 3 | 15 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | age = 19 | True 或者 False |
| != | 不等于 | age != 19 | True 或者 False |
| < | 小于 | age < 19 | True 或者 False |
| <= | 小于等于 | age <= 19 | True 或者 False |
| > | 大于 | age > 19 | True 或者 False |
| >= | 大于等于 | age >= 19 | True 或者 False |
使用文本定位:
- 我们在爬取网站使用Xpath提取数据的时候,最常使用的就是Xpath的
text()方法,该方法可以提取当前元素的信息
1.2.2 语法使用
以books.xml文件为例
books.xml文件代码
<?xml version="1.0" encoding="UTF-8" ?>
<booklist>
<book type="小说">
<name>这小子真帅</name>
<author>无名</author>
<price>80.5</price>
</book>
<book type="名著">
<name>西游记</name>
<author>吴承恩</author>
<price>90.7</price>
</book>
<book type="名著">
<name>红楼梦</name>
<author>曹雪芹</author>
<price>66</price>
</book>
<book type="小说">
<name>那小子真帅</name>
<author>无名</author>
<price>58</price>
</book>
</booklist>a. 读取xml文件的方式
然而,实际应用中是要读取HTML内容,调用etree.HTML(),该方法用于解析HTML文档并返回一个ElementTree对象
方式一:使用etree.XML():
xml文件在Python中属于普通文件的方式写入,并且使用etree.XML()有一个限制,内容中不能有第一行文档声明的部分,如:
<?xml version="1.0" encoding="UTF-8" ?>不能被包含在内,所以我们要先读取第一行,然后再读取剩下的内容
with open("books.xml", "r", encoding="UTF-8") as f:
first_line = f.readline()
data = f.read()
tree = etree.XML(data)
print(tree)其中f 是一个迭代器,只出不进的容器,所以使用readline()先读取第一行,在调用read()读取剩下的内容,然后etree.XML(data)将XML格式的数据data解析成一个ElementTree对象,该对象的根元素是XML文档的根元素。
这种方式就有些比较麻烦
方式二:etree.parse()
这种方式直接传递文件参数即可
tree = etree.parse("books.xml")
print(tree)b. XPath定位节点的基本语法
(1) 获取元素节点
需求1:获取所有的name标签
- 绝对路径写法:
tag = tree.xpath("/booklist/book/name")
print(tag)注意:xpath的结果是一个列表,列表中的元素是匹配到的节点对象(元素节点,文本节点或属性节点)
- 相对路径写法
最好先确定基础的路径,然后再开始查找,否则可能会匹配到不需要的标签
tag1 = tree.xpath("//name")
print(tag1)需求2:获取book标签下的的name标签
假设此次booklist标签下有一个name标签
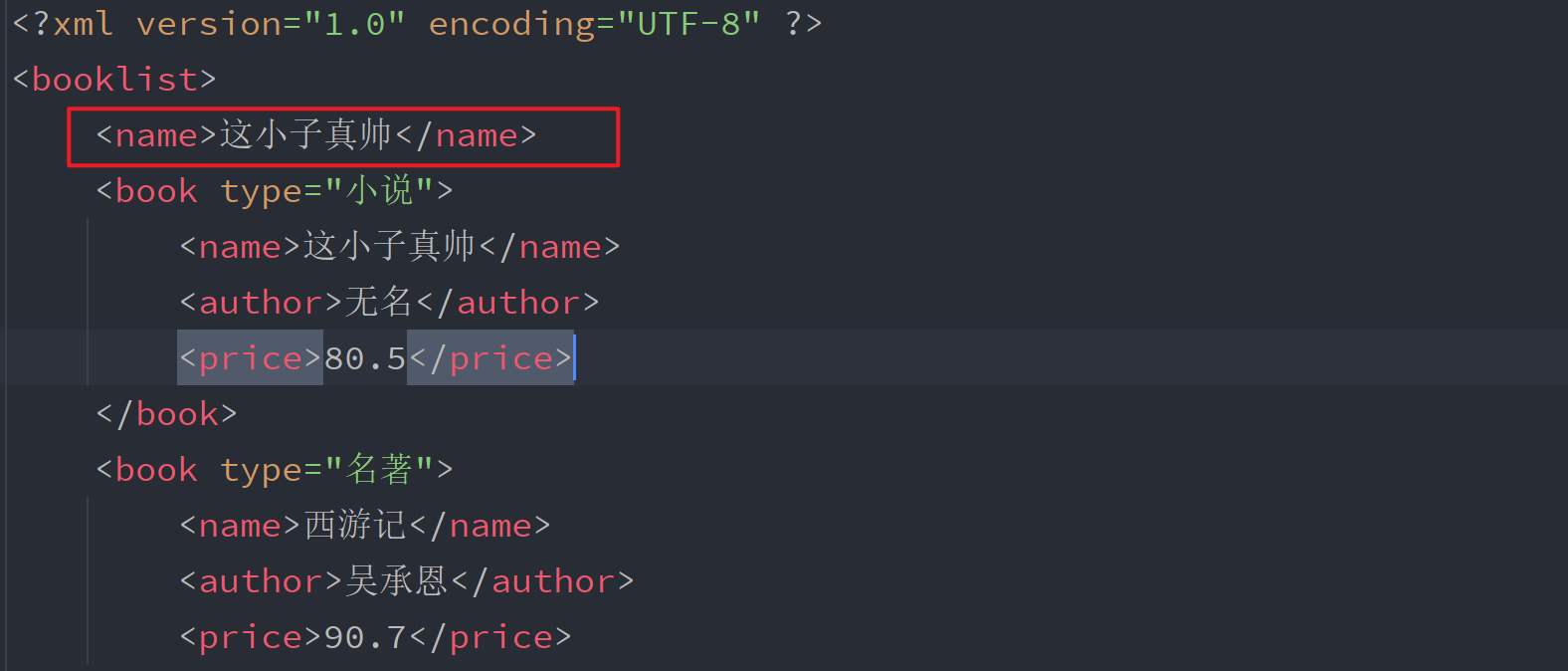
如果按照前面的写法,这个标签也会被添加到结果中。我们可以先确定book标签,再以book为基础进行定位,在以book标签定位,注意:写法是./name而不是/name
/name依然表示从根节点开始查找
./name表示从当前book标签查找
books = tree.xpath("//book")
for book in books:
# 以book为基础进行定位
name = book.xpath("./name")
# 注意:/name依然表示从根节点开始查找 ./name表示从当前book标签查找
print(name)(2) 获取标签的属性
格式:路径/@属性名
需求:获取book标签的type属性
types = tree.xpath("//book/@type")
print(types)(3) 获取文本
格式:路径/text()
需求1:获取name标签中的所有文本
names = tree.xpath("//book/name/text()")
print(names)需求1:获取price标签中的所有文本
prices = tree.xpath("//book/price/text()")
print(prices)(4) 筛选数据
筛选数据这里就用到了比较运算符: > < >= <= = != ,其中这里的判断相等使用的是一个=
需求1:获取价格大于80的书籍名称
names = tree.xpath("//book[price >80]/name/text()")
print(names)需求2:获取类型为小说的的书籍名称
names = tree.xpath("//book[@type='小说']/name/text()")
print(names)总结:
- 根据子节点设置条件,则
路径/[子标签=xxx] - 根据标签的属性设置条件,则
路径/[@属性名=xxx]
需求3:获取书名中包含“真帅”的书籍的价格
这里筛选需要用到一个方法contains(),格式为:contains(子节点名 或者 @属性名,指定内容)
prices = tree.xpath("//book[contains(name,'真帅')]/price/text()")
print(prices)需求4:获取书名以“这”开头的书籍的名称
xpath中提供了一个类似字符串的startswith()的方法,叫starts-with()
格式为:starts-with(子节点名 或者 @属性名,指定内容)
names = tree.xpath("//book[starts-with(name,'这')]/name/text()")
print(names)需求5:获取书名以“帅”结尾的书籍的名称
xpath没有提供类似字符串的 endswith() 方法,但是我们可以曲线救国,利用string-length()和substring()
string-length()方法格式:string-length(子节点名 或者 @属性名);作用:获取内容长度
substring()方法格式:substring(子节点名 或者 @属性名,起始位置,提取元素的个数);作用:根据指定的位置,指定的个数,截取字符串
思路:我们可以获取整个字符串的长度和子字符串的长度,然后对比两个是否相等,xpath中文本的索引从1开始,所以
起始位置:整个字符串的长度 - 子字符串的长度 + 1
即:substring(name,string-length(name) - string-length("帅") + 1,n)
names = tree.xpath("//book[substring(name,string-length(name)-string-length('帅')+1,1)='帅']/name/text()")
print(names)需求6:获取包含“真帅”,并且价格在80以上的书的名称
names = tree.xpath("//book[contains(name,'真帅') and price > 80]/name/text()")
print(names)(5) 谓语定位
需求1:获取第一本书的名称
注意点:索引是从1开始的
name = tree.xpath("/booklist/book[1]/name/text()")
print(name)需求2:获取最后一本书的名称
可以调用last()函数
name = tree.xpath("/booklist/book[last()]/name/text()")
print(name)需求3:获取第二本书的名称
- 方式一
使用索引,索引是从1开始的
name = tree.xpath("/booklist/book[2]/name/text()")
print(name)- 方式二
使用position()函数
name = tree.xpath("/booklist/book[position()=2]/name/text()")
print(name)需求3:获取倒数第二本书的名称
name = tree.xpath("/booklist/book[last() -1]/name/text()")
print(name)需求4:获取前三本书的名称
names = tree.xpath("/booklist/book[position() <= 3]/name/text()")
print(names)需求5:获取某个标签下的所有子标签
使用通配符*表示
names = tree.xpath("/booklist/book/*/text()")
print(names)c. 完整代码
from lxml import etree # 导入了Python中的lxml库中的etree模块,etree主要用来解析树结构
# 1.读取xml文件的方式
"""
实际应用中:是要读取HTML内容,调用etree.HTML(),该方法用于解析HTML文档并返回一个ElementTree对象
"""
# 首先要读取文件内容
# 注意点:xml文件在Python中属于普通文件的方式写入,
# 方式一:etree.XML()
# 注意:使用该方法操作,内容中不能有第一行文档声明的部分
# f 是一个迭代器,只出不进的容器
with open("books.xml", "r", encoding="UTF-8") as f:
# 先读取第一行
first_line = f.readline()
# 然后读取剩下的内容
data = f.read() # 将XML格式的数据data解析成一个ElementTree对象该对象的根元素是XML文档的根元素。
tree = etree.XML(data)
print(tree)
# 方式二:etree.parse()
tree = etree.parse("books.xml")
print(tree)
# 2.XPath定位节点的基本语法:重点掌握
# a.获取元素节点
# 需求1:获取所有的`name`标签
# 注意:xpath的结果是一个列表,列表中的元素是匹配到的节点对象(元素节点,文本节点或属性节点)
# 绝对路径
tag = tree.xpath("/booklist/book/name")
print(tag)
# 相对路径
# 注意:最好先确定基础的路径,然后再开始查找,否则可能会匹配到不需要的标签
tag1 = tree.xpath("//name")
print(tag1)
# 先确定book标签
books = tree.xpath("//book")
for book in books:
# 以book为基础进行定位
name = book.xpath("./name")
# 注意:/name依然表示从根节点开始查找 ./name表示从当前book标签查找
print(name)
# b.获取标签的属性,格式:路径/@属性名
# 需求2:获取`book`标签下的的`name`标签
types = tree.xpath("//book/@type")
print(types)
# c.获取文本,格式:路径/text()
# 需求1:获取name标签中的所有文本
names = tree.xpath("//book/name/text()")
print(names)
# 需求1:获取price标签中的所有文本
prices = tree.xpath("//book/price/text()")
print(prices)
# d.筛选数据
# 用到比较运算符: > < >= <= = != ,其中这里的判断相等使用的是一个=
# 需求1:获取价格大于80的书籍名称
names = tree.xpath("//book[price >80]/name/text()")
print(names)
# 需求2:获取类型为小说的的书籍名称
names = tree.xpath("//book[@type='小说']/name/text()")
print(names)
"""
总结:
根据子节点设置条件,则 路径/[子标签=xxx]
根据标签的属性设置条件,则 路径/[@属性名=xxx]
"""
# 需求3:获取书名中包含“真帅”的书籍的价格
# contains(子节点名 或者 @属性名,指定内容)
prices = tree.xpath("//book[contains(name,'真帅')]/price/text()")
print(prices)
# 需求4:获取书名以“这”开头的书籍的名称
# starts-with(子节点名 或者 @属性名,指定内容)
names = tree.xpath("//book[starts-with(name,'这')]/name/text()")
print(names)
# 需求5:找出书名以“帅”结尾的书籍的名称
'''
这小子真帅----》帅
5 1
5 - 1 + 1,从5位置开始获取,需要提取的子字符串为1
起始位置:整个字符串的长度 - 子字符串的长度 + 1
substring(name,string-length(name) - string-length("帅") + 1,n)
'''
# string-length(子节点名 或者 @属性名):内容长度
# substring(子节点名 或者 @属性名,起始位置,提取元素的个数):根据指定的位置,指定的个数,截取字符串
print(tree.xpath("//book[substring(name,string-length(name)-string-length('帅')+1,1)='帅']/name/text()"))
# 需求6:获取包含“真帅”,并且价格在80以上的书的名称
names = tree.xpath("//book[contains(name,'真帅') and price > 80]/name/text()")
print(names)
# d.谓语定位
# 需求1:获取第一本书的名称
name = tree.xpath("/booklist/book[1]/name/text()")
print(name)
# 需求2:获取最后一本书的名称
name = tree.xpath("/booklist/book[last()]/name/text()")
print(name)
# 需求3:获取第二本书的名称
# 方式一:
name = tree.xpath("/booklist/book[2]/name/text()")
print(name)
# 方式二:
name = tree.xpath("/booklist/book[position()=2]/name/text()")
print(name)
# 需求4:获取倒数第二本书的名称
name = tree.xpath("/booklist/book[last() -1]/name/text()")
print(name)
# 需求5:获取前三本书的名称
names = tree.xpath("/booklist/book[position() <= 3]/name/text()")
print(names)
# 需求6:获取某个标签下的所有子标签
# 使用通配符*表示
names = tree.xpath("/booklist/book/*/text()")
print(names)






暂无评论内容