1、前言
我们在进行爬虫的过程中,服务器经常为了校验是否是机器人操作,会使用验证码进行判断
-
常见的验证码格式:
-
数字字母验证码
-
滑块验证码
-
点字验证码
-
-
破解验证码的方式有:
-
光学文字识别:ddddocr,需要通过
pip install ddddocr -
注意:ddddocr只能破解文字和滑块验证码,对于点字验证码有限制
-
超级鹰平台
-
2、数字验证码
2.1 核心操作步骤
以光学文字识别的方式为例
- 定位到数字验证码对应的标签
- 对验证码图片实现截图操作
- 通过ddddocr识别图片上的数字
2.2 使用案例
以破解http://coding.1000phone.com/userLogin,登录的验证码为例
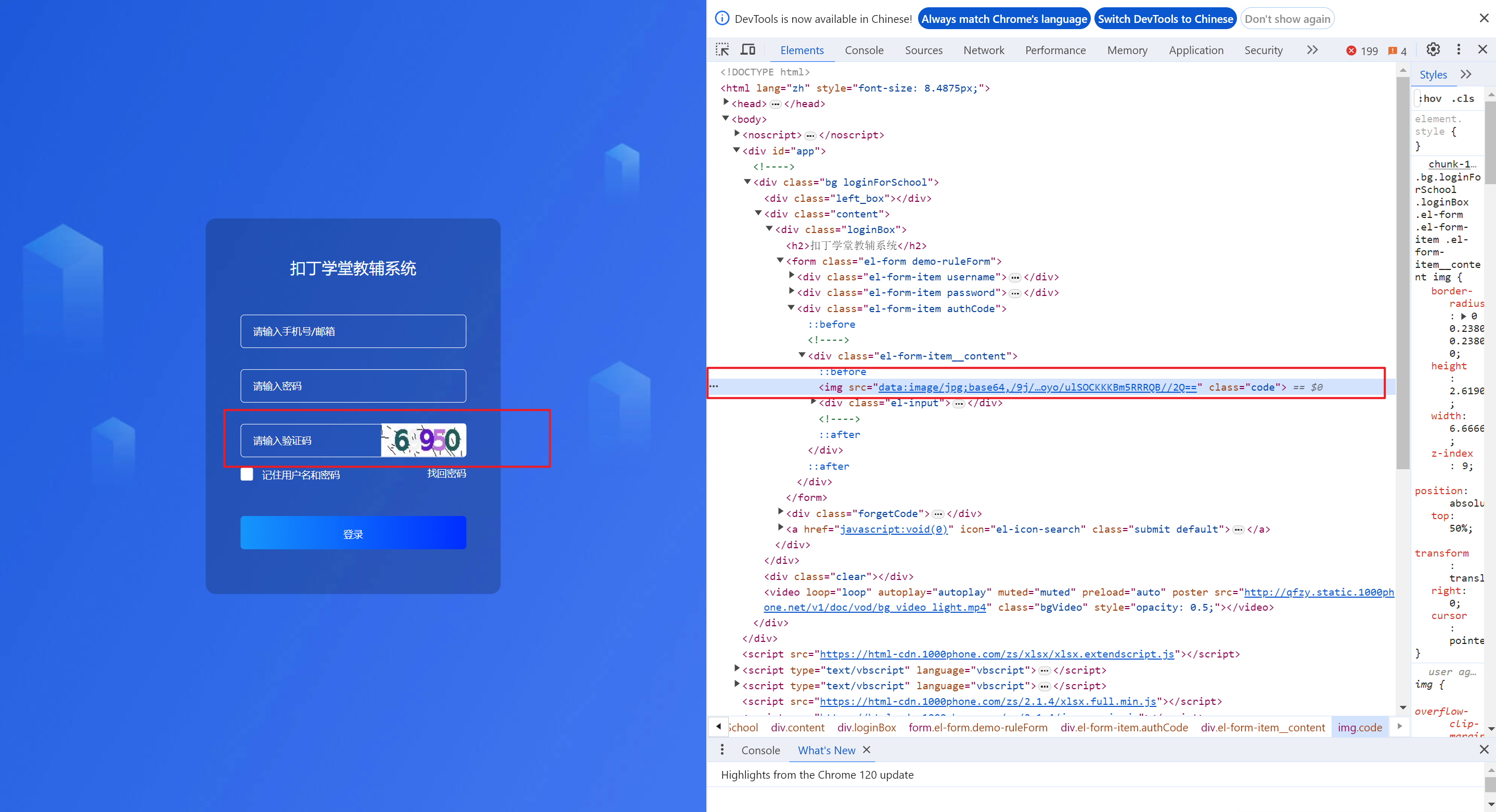
2.2.1 分析
这里我们使用Selenium的方式,所以首先我们要创建一个Chrome对象,并且打开网站。然后我们就可以通过标签定位到数字验证码对应的标签,配合F12检查网页元素的视角,可以使用CSS选择器的方式定位。定位到该标签,就可以直接调用screenshot()方法将图片保存下来,然后就可以获取图片的字节数据,这里需要注意的是,图片在Python中是属于二进制文件类型。
获取到验证码图片的字节数据,下面就可以对它进行识别了,首先需要创建一个ddddocr对象,然后直接调用classification()方法,将字节数据进行识别,并且转换成字符串,最后打印输出,在和保存的图片比较,是一致的
2.2.2 完整代码
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import time
import ddddocr
# 1.创建Chrome对象并打开网站
url = "http://coding.1000phone.com/userLogin"
browser = Chrome()
browser.get(url)
browser.maximize_window()
time.sleep(2)
# 2.获取验证码的图片,定位到验证码的标签
code_img = browser.find_element(by=By.CSS_SELECTOR, value=".code")
# 进行截图操作,获取到图片
code_img.screenshot(r"images/number_code.png")
# 获取截图的字节数据,图片在Python中属于二进制文件
code_img_bytes = code_img.screenshot_as_png
print(code_img_bytes)
# 3.创建ddddocr对象,识别图片字节数据进识别
docr = ddddocr.DdddOcr(show_ad=False)
# 对图片字节数据进行识别,转换为字符串
code = docr.classification(code_img_bytes)
print('验证吗:', code)2.3 实战练习
2.3.1 需求
- 破解阿里企业邮箱验证码
- https://qiye.aliyun.com/
2.3.2 分析
-
这个网站的验证码默认不显示出来,只有输入邮箱和密码并且点击隐私政策按钮后,再点击登录按钮才会出现

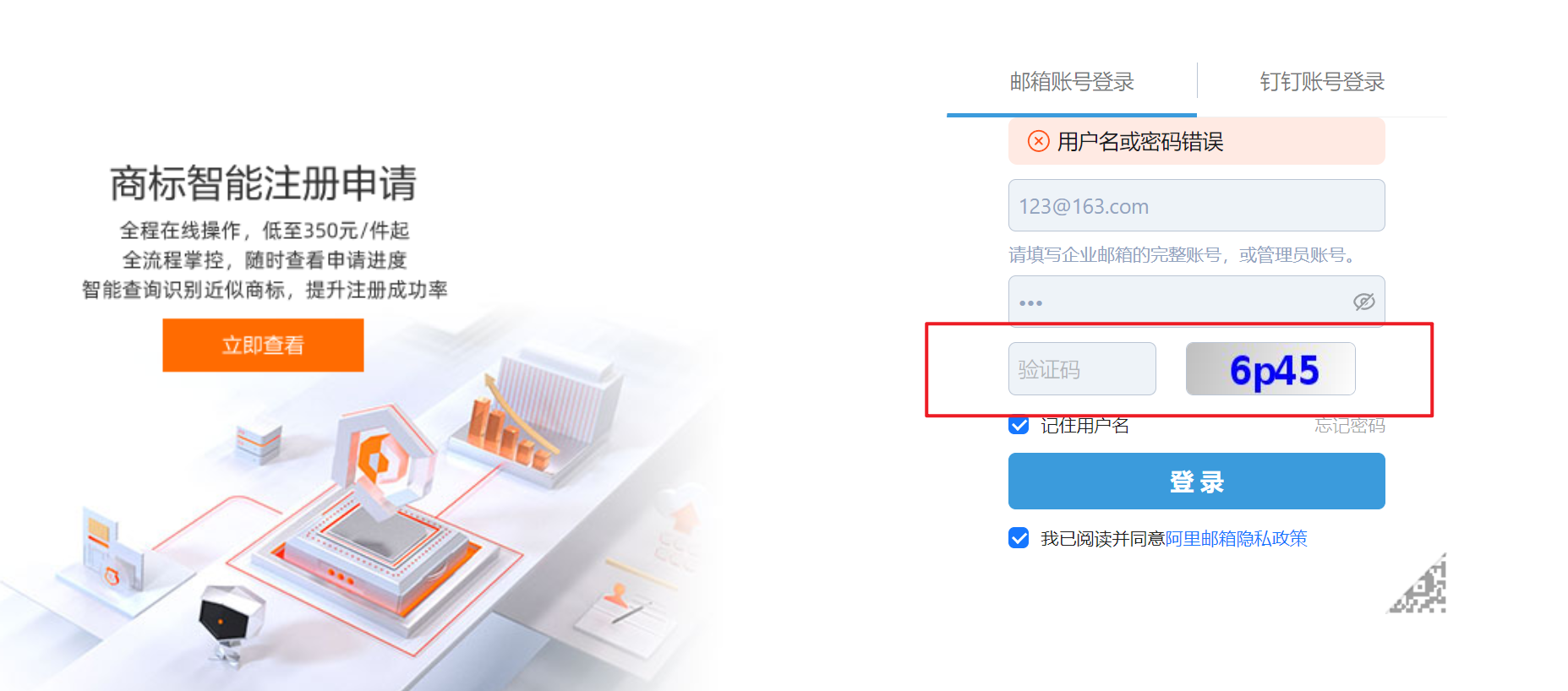
-
所以我们需要模拟这个过程,首先需要创建一个
Chrome对象,然后调用get()方法打开网站browser = Chrome() url = 'http://mail.1000phone.com/' browser.get(url) time.sleep(2) -
然后我们要定位到用户名和密码的input标签
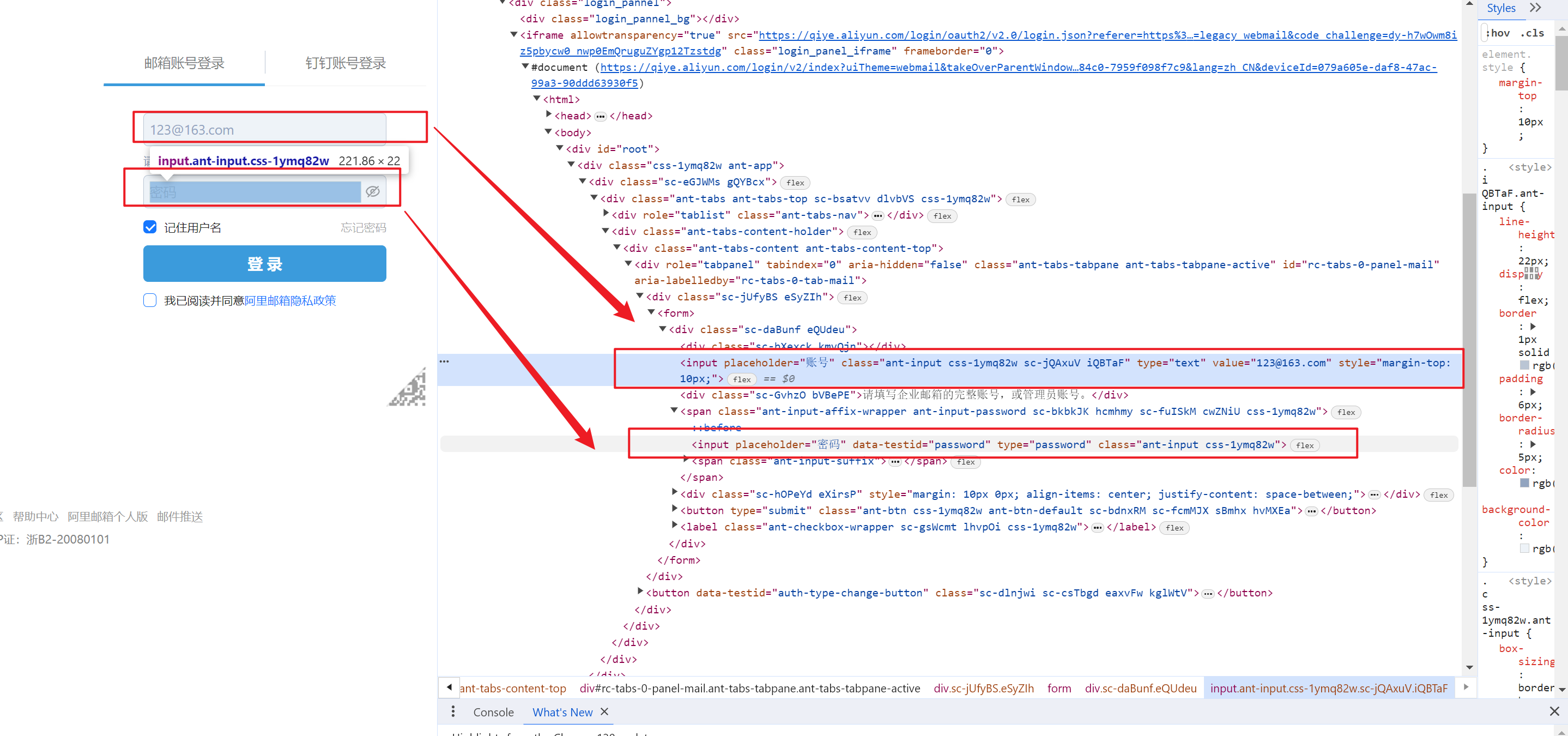
username_input = browser.find_element(by=By.XPATH,value='//input[@class="ant-input css-1ymq82w sc-jQAxuV iQBTaF"]') pwd_input = browser.find_element(by=By.XPATH,value='//input[@class="ant-input css-1ymq82w"]') -
但是在这里我们进行测试,就会发现一个问题,标签会定位不到,所以我们再检查一下网页元素,可以发现,这里包含了一个隐式窗口,所以我们定位到
iframe标签,然后调用switch_to.frame()需要切换至隐式窗口中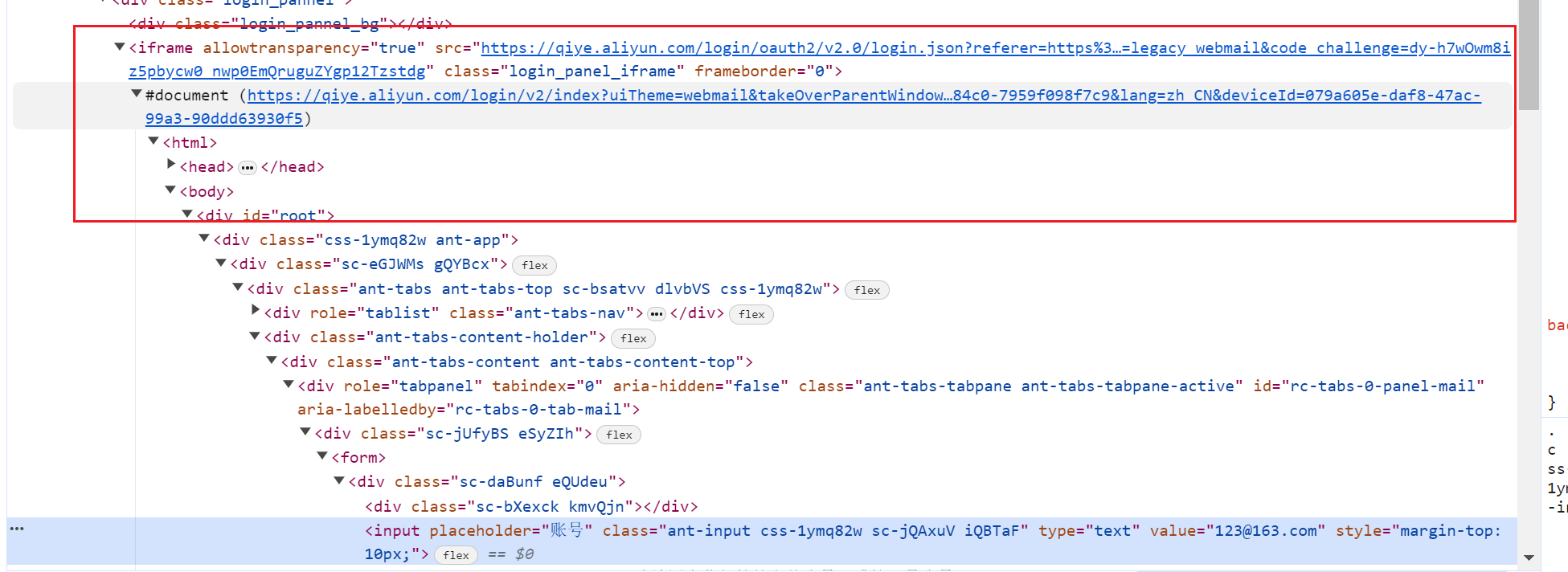
iframe = browser.find_element(by=By.CSS_SELECTOR, value=".login_panel_iframe") browser.switch_to.frame(iframe) -
在测试一下,不会报错,那么我们就可以通过
send_keys()方法输入数据,然后定位到隐私政策的按钮,调用click()方法点击隐式政策的按钮,最后点击登录的按钮username_input.send_keys("qwer@163.com") pwd_input.send_keys("1234") # 定位到条款按钮,并点击 checkbox_button = browser.find_element(by=By.XPATH, value="//span[@class='ant-checkbox css-1ymq82w']") checkbox_button.click() # 定位到登录按钮,并点击 login_button = browser.find_element(by=By.CSS_SELECTOR, value=".hvMXEa") login_button.click() -
到这里的时候,验证码就会弹出来,从而我们就可以进行图片的定位了,并且调用
screenshot()的方法,截取图片,并且调用screenshot_as_png获取图片的字节数据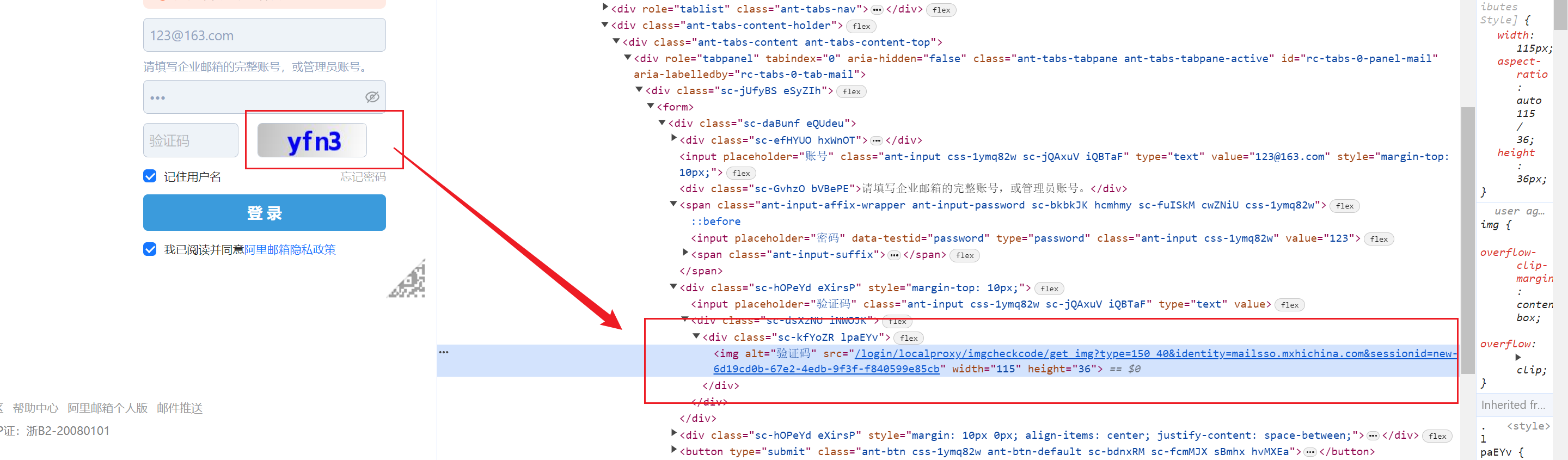
# 定位验证码标签 code_img = browser.find_element(by=By.XPATH, value="//div[@class='sc-kfYoZR lpaEYv']/img") # 截图,获取图片 code_img.screenshot(r"images/aliyun_code.png") # 获取图片的字节数据 code_img_bytes = code_img.screenshot_as_png -
下面就使用
dddocr库,先创建一个ddddocr对象,然后调用来classification()方法解析图片,转换成字符串# 创建一个dddocr对象 docr = ddddocr.DdddOcr(show_ad=False) # 解析图片字节数据,转换成字符串 code = docr.classification(code_img_bytes) print("验证码:", code) -
最后,定位验证码的输入框,并调用
send_keys()方法将获取到的验证码,写入到输入框中code_input = browser.find_element(by=By.XPATH, value="//div[@class='sc-hOPeYd eXirsP']/input") code_input.send_keys(code)
2.3.3 完整代码
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import time
import ddddocr
# 1.创建Chrome对象并且打开网站
url = "https://qiye.aliyun.com/"
browser = Chrome()
browser.get(url)
browser.maximize_window()
time.sleep(2)
# 2.切换iframe,隐式窗口
iframe = browser.find_element(by=By.CSS_SELECTOR, value=".login_panel_iframe")
browser.switch_to.frame(iframe)
# 3.定位用户名和密码的input标签
# 注意:定位标签的时候,定位不到,很有可能存在隐式窗口
username_input = browser.find_element(by=By.CSS_SELECTOR, value=".iQBTaF")
pwd_input = browser.find_element(by=By.XPATH, value="//input[@class='ant-input css-1ymq82w']")
# 4.输入数据,并点击登录按钮
username_input.send_keys("qwer@163.com")
pwd_input.send_keys("1234")
# 定位到条款按钮,并点击
checkbox_button = browser.find_element(by=By.XPATH, value="//span[@class='ant-checkbox css-1ymq82w']")
checkbox_button.click()
# 定位到登录按钮,并点击
login_button = browser.find_element(by=By.CSS_SELECTOR, value=".hvMXEa")
login_button.click()
time.sleep(2)
# 5. 开始捕捉图片
# 定位验证码标签
code_img = browser.find_element(by=By.XPATH, value="//div[@class='sc-kfYoZR lpaEYv']/img")
# 截图,获取图片
code_img.screenshot(r"images/aliyun_code.png")
# 获取图片的字节数据
code_img_bytes = code_img.screenshot_as_png
# 6.解析验证码
# 创建一个dddocr对象
docr = ddddocr.DdddOcr(show_ad=False)
# 解析图片字节数据,转换成字符串
code = docr.classification(code_img_bytes)
print("验证码:", code)
# 7.写入验证码
code_input = browser.find_element(by=By.XPATH, value="//div[@class='sc-hOPeYd eXirsP']/input")
code_input.send_keys(code)
time.sleep(5)





暂无评论内容