1、前言
我们在进行爬虫的过程中,服务器经常为了校验是否是机器人操作,会使用验证码进行判断
-
常见的验证码格式:
-
数字字母验证码
-
滑块验证码
-
点字验证码
-
-
破解验证码的方式有:
-
光学文字识别:ddddocr,需要通过
pip install ddddocr -
注意:ddddocr只能破解文字和滑块验证码,对于点字验证码有限制
-
超级鹰平台
-
2、滑块验证码
2.1 知识储备
- 图片是由像素组成的 ,把图片转化为数据的话,是3维的
- 像素是由位置和颜色组成的 ,位置[坐标系 有x轴 有y轴],这是二维的
- 第三维度就是颜色,颜色是由
rgb三原色按照颜色亮度展示不同的色彩的r(red) g(green) b(blue)每个颜色的亮度值是从0到255的- 数值越小,表示颜色越暗 ,所以当三个颜色值都为0的时候就是黑色,当三个颜色值都是255时就是白色
- 使用的时候使用不到第三个维度 ,因为不是去修改颜色的值 ,只会用到位置这个信息 ,坐标[二维的] ,x轴和y轴
使用案例
import cv2
# 1.读取图片的数据,将图片转换为一个三维的列表(数组)
img_data = cv2.imread(r"images/number_code.png")
print(img_data)
# 查看数据的形状,(y轴,x轴,颜色亮度的个数)
print(img_data.shape)
# 使用类似于列表
# 2.定位y轴,再定位x轴,使用下标索引进行定位
# a.获取y为0的数据集,结果为二维
print(img_data[0])
# b.获取y为2-5的数据,切片操作,结果为三维
print(img_data[2:5])
# c.取y轴所有的数据
print(img_data[:])
# d.定位x,定位x=0的数据
# 方式一
print(img_data[0][0])
# 方式二
print(img_data[0, 0])
# e.定位所有的y,x为0
print(img_data[:, 0])
# f.定位所有的y,x为1-30
print(img_data[:, 1:30])2.2 破解步骤
- 获取到带有滑块和缺口的背景标签,设置为
图片A - 单独拿到滑块,设置为
图片B - 利用ddddocr获取B在A上第一次出现的位置
pos1 - 将这个位置的数据打乱形成
图片C【将B在A第一次出现的位置打成马赛克】 - 在图片C上找B第一次出现的位置
pos2,此时定位到的是缺口 - 已知滑块的位置,缺口的位置,则两个两位的
x轴数据相减,就是滑块需要滑动的距离
2.3 使用案例
2.3.1 需求
破解豆瓣电影:https://accounts.douban.com/passport/login?source=movie
登录时的滑块验证码
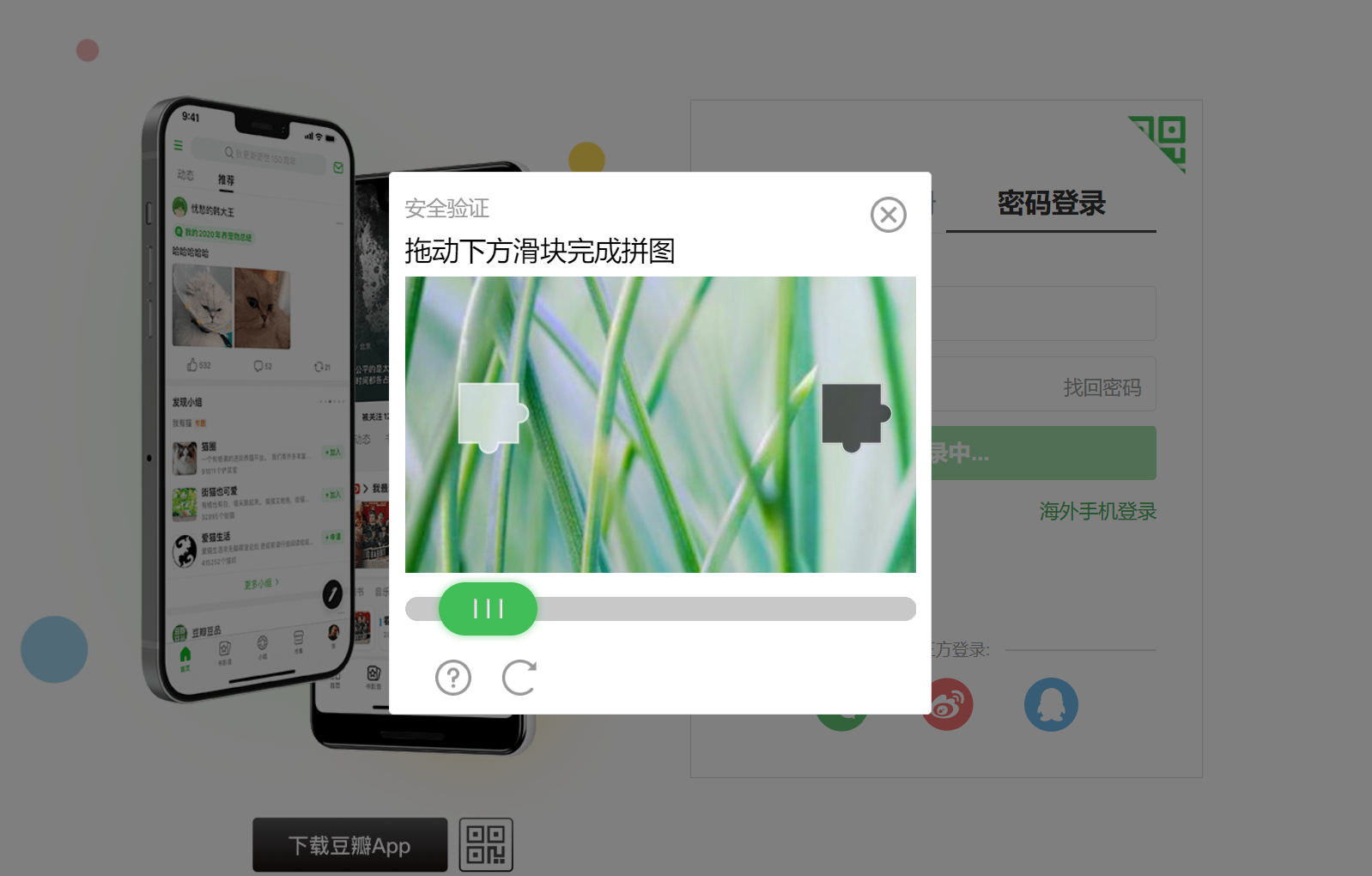
2.3.2 分析
- 首先,我们需要创建一个浏览器对象,并且打开网页
url = "https://accounts.douban.com/passport/login?source=movie"
browser = Chrome()
browser.get(url)
browser.maximize_window()
time.sleep(2)-
但是,打开网页的时候,我们可以发现
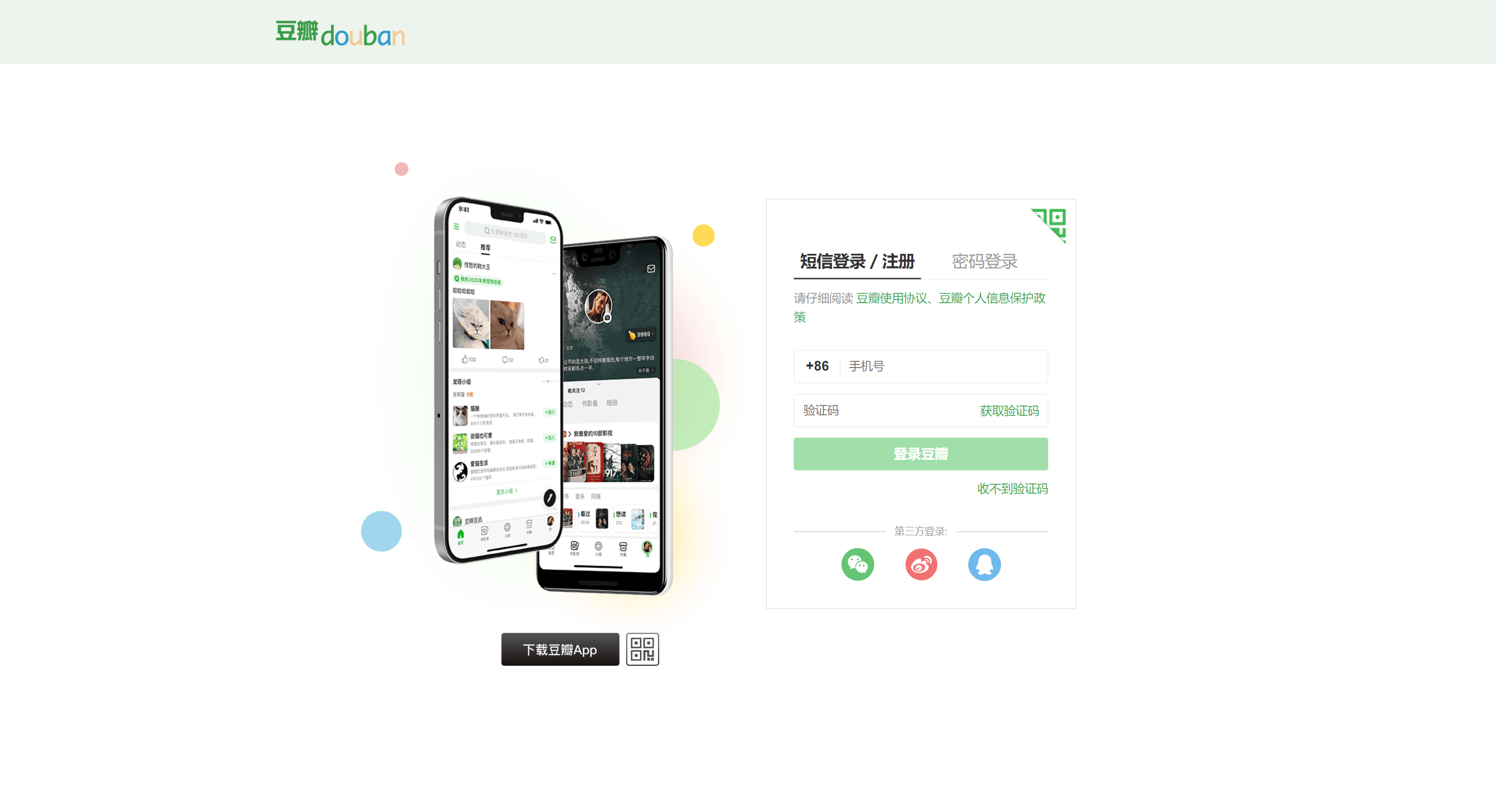
-
在这个页面中,属于短信登录和注册的,无法显示验证码,所以我们要切换至密码登录的选项中,然后,输入手机号码和密码,并且点击豆瓣按钮,使验证码出现
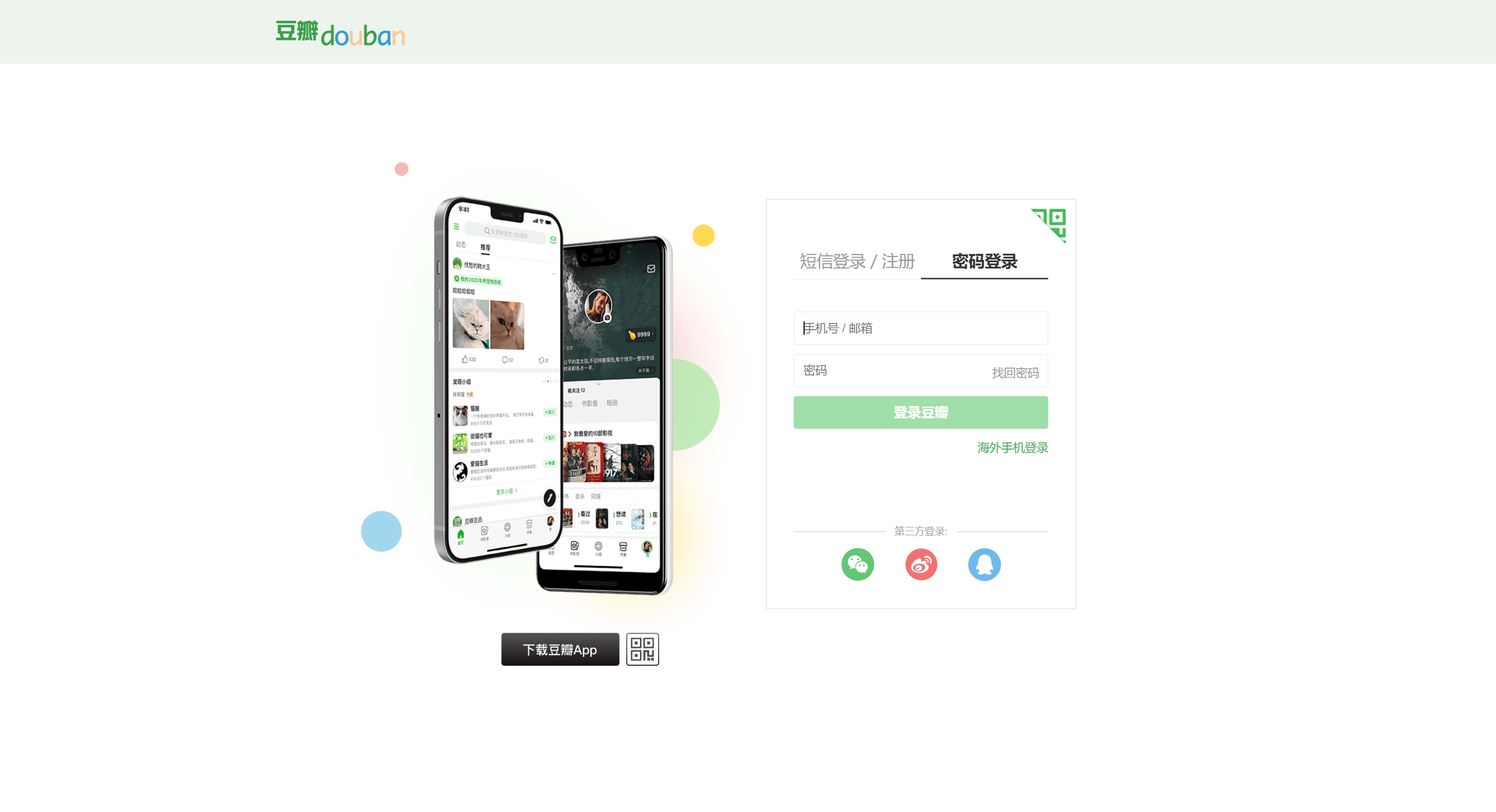
- 所以,我们首先需要定位密码登录所有在标签,并且进行点击事件
login_li = browser.find_element(by=By.CSS_SELECTOR, value='.account-tab-account') login_li.click()- 进行到这一步的时候,网页的登录显示页面将被切换,下面我们就需要定位账号和密码的输入框,并且添加写入事件,即使用
send_keys()方法
# 账号输入框 user_input = browser.find_element(by=By.CSS_SELECTOR, value=".account-form-input") user_input.send_keys("1234567890") # 密码输入框 pwd_input = browser.find_element(by=By.XPATH, value="//input[@class='account-form-input password']") pwd_input.send_keys("QWEasd123")- 最后,在定位登录按钮,并且添加点击事件
pwd_login_btn = browser.find_element(by=By.CSS_SELECTOR, value=".account-form-field-submit") pwd_login_btn.click()- 这里有一个注意点,我们需要在浏览器进行操作前和后,添加一个休眠事件,给程序一定的响应时间
-
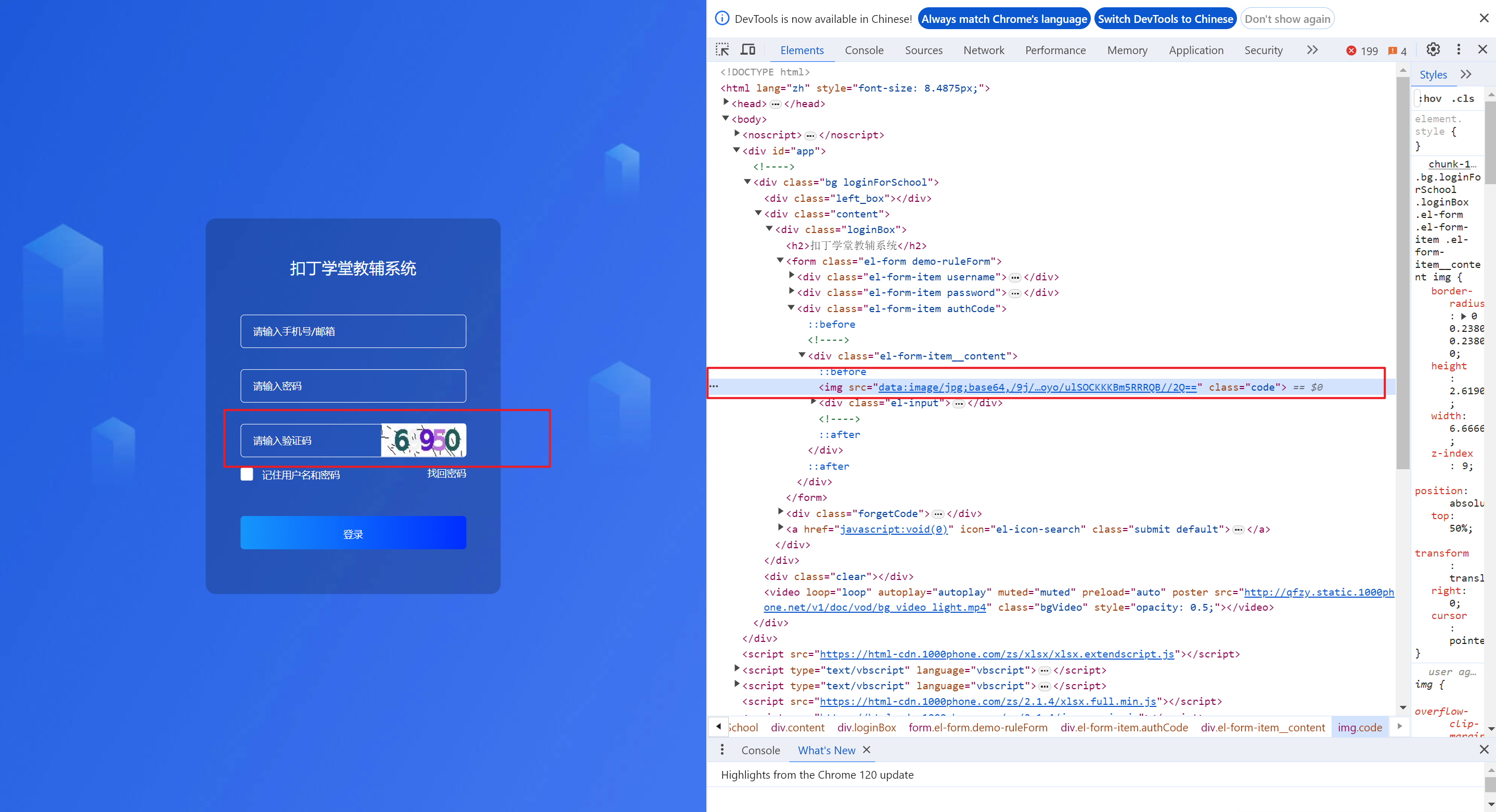
进行到这一步的时候,网页中就可以出现验证码了,那么下面我们就可以进行破解了
-
通过观察网页检查元素,我们可以发现,滑块验证码这部分是一个隐式窗口,所以我们需要切换至该
iframe中,即使用switch_to.frame()方法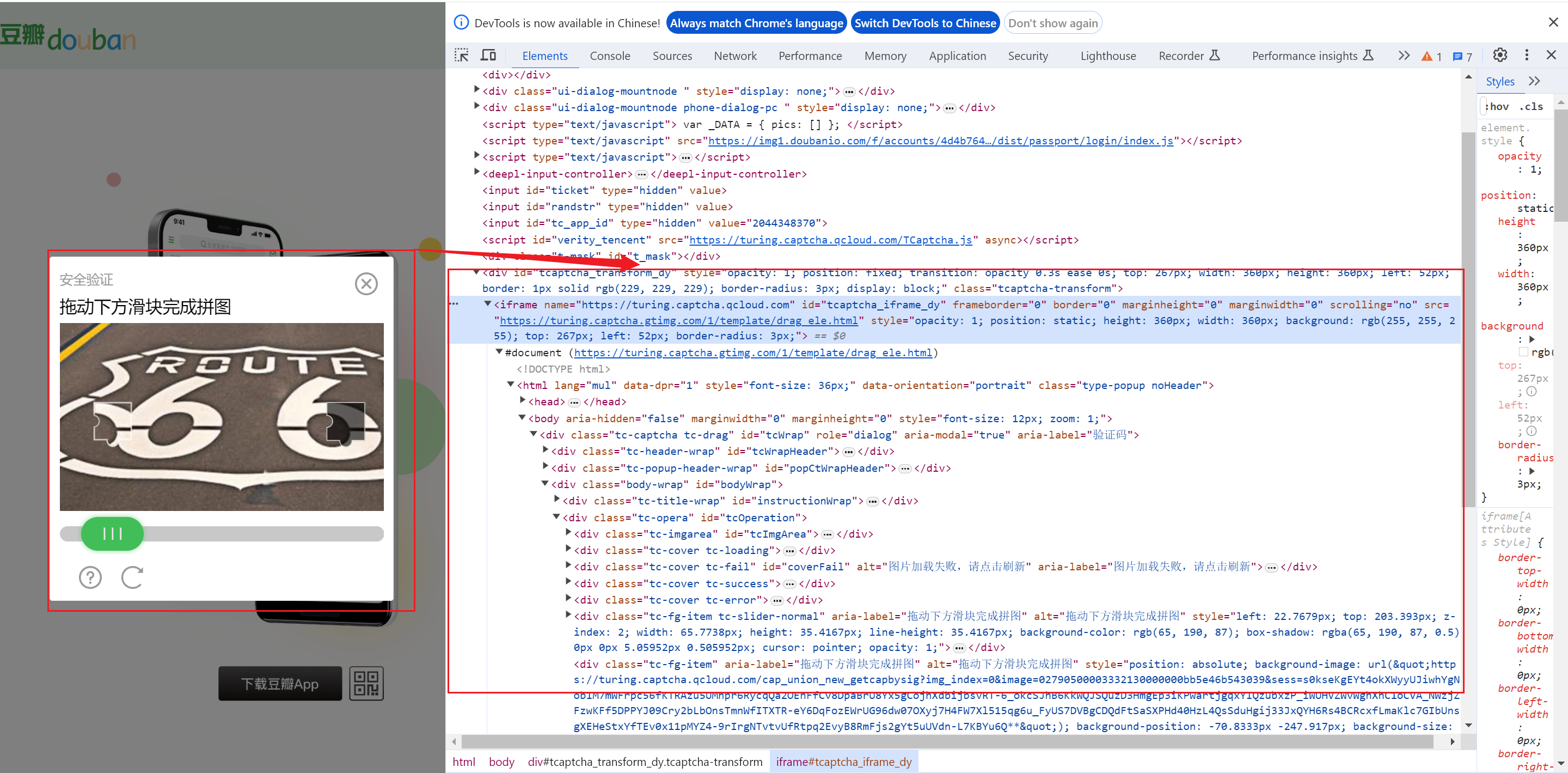
iframe = browser.find_element(by=By.ID, value="tcaptcha_iframe_dy") browser.switch_to.frame(iframe) -
然后我们定位带有滑块和缺口的背景图片A,作为
big_image,然后使用screenshot()方法截图,将验证码保存下来,并且使用screenshot_as_png获取图片的字节元素big_image = browser.find_element(by=By.ID, value='slideBg') big_image.screenshot(r'images/big_slide.png') # 获取字节数据 big_image_bytes = big_image.screenshot_as_png -
然后我们在获取其中的滑块B,作为
small_image,然后使用screenshot()方法截图,将验证码保存下来,并且使用screenshot_as_png获取图片的字节元素small_image = browser.find_element(by=By.CSS_SELECTOR, value='#tcOperation > div:nth-child(7)') small_image.screenshot(r'images/small_slide.png') # 获取字节数据 small_image_bytes = small_image.screenshot_as_png -
然后找到滑块B在图片A中第一次出现的位置,这里需要使用
ddddocr库中的slide_match()方法,里面需要传递三个参数:target_bytes参数表示查找的目标字节数据,background_bytes参数表示背景图的字节数据,simple_target表示形状简单匹配- 这里的返回结果是一个字典,并且字典中的
key为target的值是一个列表,其中的值表示左上角坐标和右下角坐标点 - 我们可以使用
get()方法拆包
ocr = ddddocr.DdddOcr(show_ad=False) pos1 = ocr.slide_match(target_bytes=small_image_bytes, # 查找的目标字节数据 background_bytes=big_image_bytes, # 背景图的字节数据 simple_target=True) # 形状简单匹配 print(pos1) # {'target_y': 0, 'target': [25, 44, 86, 105]} # 左上角坐标和右下角坐标点 x1, y1, x2, y2 = pos1.get('target') # 拆包 -
然后我们就可以在图片A上提取到这个位置,将数据打乱,即形成马赛克
数据打乱原理
间隔取值,将值的个数重复到和原数据的个数一致,让数据错乱
比如:
有一个列表
nums = [45,7,8,8,34,3,2,5],其中有8个元素;对其进行切片
num[::2],得到的结果[45,8,34,2],这是列表中有四个元素;在将列表中的数据重复2次,即得到
[45,8,34,2,45,8,34,2],实现数据打乱- 使用
cv2库的imread()方法,获取到图片数据,结果是一个三维列表
big_image_data = cv2.imread(r'images/big_slide.png') # 得到一个三维列表 print(big_image_data)-
根据前面拆包获得的坐标,定位到图片上的位置,将这个位置的数据提取出来
-
需要注意的是,需要先写
y轴坐标,在写x轴坐标
small_image_data = big_image_data[y1:y2, x1:x2] print(small_image_data.shape) # 61 * 61- 由于上面拿到的像素的大小为61 * 61,61的因数很少,所以提取的时候可以多提取一些范围,保证拿出来的形状,可以有2,3或5的因数
small_image_data = big_image_data[y1:y2 + 9, x1:x2 + 9] print(small_image_data.shape) # 70 * 70- 然后,我们可以以5为间隔,进行取值
shuffle_data = small_image_data[::5, ::5]-
然后重复5次,恢复到原来的形状
-
这里需要使用
numpy库的np.repeat()方法,其中参数axis控制的是轴重复,axis=0表示y轴重复,axis=1表示x轴重复
shuffle_data = np.repeat(shuffle_data, 5, axis=0) shuffle_data = np.repeat(shuffle_data, 5, axis=1)- 最后将打乱之后的数据覆盖原本的数据,并且保存成图片C
big_image_data[y1:y2 + 9, x1:x2 + 9] = shuffle_data cv2.imwrite(r'images/big_shuffle.png', big_image_data)- 到这里,我们简单运行一下程序,查看截图,可以发现,图片中的滑块部分已经变成了马赛克

- 使用
-
然后我们在打了马赛克之后的图片上找和滑块B形状相同的位置,同样会得到两个坐标,并且对之前获得的坐标中的一个X轴坐标,进行相减,既可以获得一个差值,即滑块需要移动的距离
with open(r'images/big_shuffle.png', 'rb') as f: big_shuffle_bytes = f.read() # 对比 pos2 = ocr.slide_match(target_bytes=small_image_bytes, # 查找的目标字节数据 background_bytes=big_shuffle_bytes, # 背景图的字节数据 simple_target=True) x11, y11, x22, y22 = pos2.get('target') # 滑块需要滑动的距离 distance = x11 - x1 -
然后我们就可以定位滑块,进项滑动,
- 这里是执行拖拽时间,所以我么需要创建一个action对象,然后使用
drag_and_drop_by_offset().perform()进行实现
slider_btn = browser.find_element(by=By.CSS_SELECTOR, value='#tcOperation > div:nth-child(6)') # 执行拖拽事件 action = ActionChains(browser) action.drag_and_drop_by_offset(slider_btn, distance, 0).perform() - 这里是执行拖拽时间,所以我么需要创建一个action对象,然后使用
2.3.3 完整代码
import cv2
import numpy as np
from selenium.webdriver import Chrome, ActionChains
from selenium.webdriver.common.by import By
import time
import ddddocr
# 1.创建Chrome对象并打开网页
url = "https://accounts.douban.com/passport/login?source=movie"
browser = Chrome()
browser.get(url)
browser.maximize_window()
time.sleep(2)
# 2.定位到密码登录的标签并点击
login_li = browser.find_element(by=By.CSS_SELECTOR, value='.account-tab-account')
login_li.click()
# 3.定位账号和密码输入框,并且输入数据
# 账号输入框
user_input = browser.find_element(by=By.CSS_SELECTOR, value=".account-form-input")
user_input.send_keys("1234567890")
# 密码输入框
pwd_input = browser.find_element(by=By.XPATH, value="//input[@class='account-form-input password']")
pwd_input.send_keys("QWEasd123")
# 4.定位登录按钮点击
pwd_login_btn = browser.find_element(by=By.CSS_SELECTOR, value=".account-form-field-submit")
pwd_login_btn.click()
time.sleep(5)
# 5.定位并切换滑块的iframe
iframe = browser.find_element(by=By.ID, value="tcaptcha_iframe_dy")
browser.switch_to.frame(iframe)
# 6.定位带有滑块和缺口的背景图片A
big_image = browser.find_element(by=By.ID, value='slideBg')
big_image.screenshot(r'images/big_slide.png')
# 获取字节数据
big_image_bytes = big_image.screenshot_as_png
time.sleep(3)
# 7.获取滑块图片B
small_image = browser.find_element(by=By.CSS_SELECTOR, value='#tcOperation > div:nth-child(7)')
small_image.screenshot(r'images/small_slide.png')
# 获取字节数据
small_image_bytes = small_image.screenshot_as_png
# 8.找到滑块B在图片A中第一次出现的位置
ocr = ddddocr.DdddOcr(show_ad=False)
pos1 = ocr.slide_match(target_bytes=small_image_bytes, # 查找的目标字节数据
background_bytes=big_image_bytes, # 背景图的字节数据
simple_target=True) # 形状简单匹配
print(pos1) # {'target_y': 0, 'target': [25, 44, 86, 105]} # 左上角坐标和右下角坐标点
x1, y1, x2, y2 = pos1.get('target') # 拆包
# 9.在图片A上提取到这个位置,将数据打乱【马赛克】
big_image_data = cv2.imread(r'images/big_slide.png') # 得到一个三维列表
print(big_image_data)
time.sleep(3)
# 根据坐标,定位到图片上的位置,将这个位置的数据提取出来
small_image_data = big_image_data[y1:y2, x1:x2]
print(small_image_data.shape) # 61 * 61
'''
打乱数据的原理:
间隔取值,将值的个数重复到和原数据的个数一致,让数据错乱
如:
nums = [45,7,8,8,34,3,2,5]
----->num[::2]----->[45,8,34,2]----->将序列中的数据重复2次-----》[45,8,34,2] * 2---->[45,8,34,2,45,8,34,2]
由于上面拿到的像素的大小为61 * 61,61的因数很少,所以提取的时候可以多提取一些范围,保证拿出来的形状,可以有2,3或5的因数
'''
small_image_data = big_image_data[y1:y2 + 9, x1:x2 + 9]
print(small_image_data.shape) # 70 * 70
time.sleep(3)
# 以5为间隔,取值
shuffle_data = small_image_data[::5, ::5]
# 重复5次,恢复到原来的形状,np.repeat():axis控制的是轴重复,axis=0表示y轴重复,axis=1表示x轴重复
shuffle_data = np.repeat(shuffle_data, 5, axis=0)
shuffle_data = np.repeat(shuffle_data, 5, axis=1)
# 将打乱之后的数据覆盖原本的数据
big_image_data[y1:y2 + 9, x1:x2 + 9] = shuffle_data
# 将打乱之后得到的数据保存成图片C
cv2.imwrite(r'images/big_shuffle.png', big_image_data)
time.sleep(3)
# 10.在打了马赛克之后的图片上找和滑块B形状相同的位置
with open(r'images/big_shuffle.png', 'rb') as f:
big_shuffle_bytes = f.read()
# 对比
pos2 = ocr.slide_match(target_bytes=small_image_bytes, # 查找的目标字节数据
background_bytes=big_shuffle_bytes, # 背景图的字节数据
simple_target=True)
x11, y11, x22, y22 = pos2.get('target')
# 滑块需要滑动的距离
distance = x11 - x1
# 11.拖动滑块进行滑动
slider_btn = browser.find_element(by=By.CSS_SELECTOR, value='#tcOperation > div:nth-child(6)')
# 执行拖拽事件
# 创建action对象
action = ActionChains(browser)
action.drag_and_drop_by_offset(slider_btn, distance, 0).perform()






暂无评论内容