
爬虫共13篇
排序
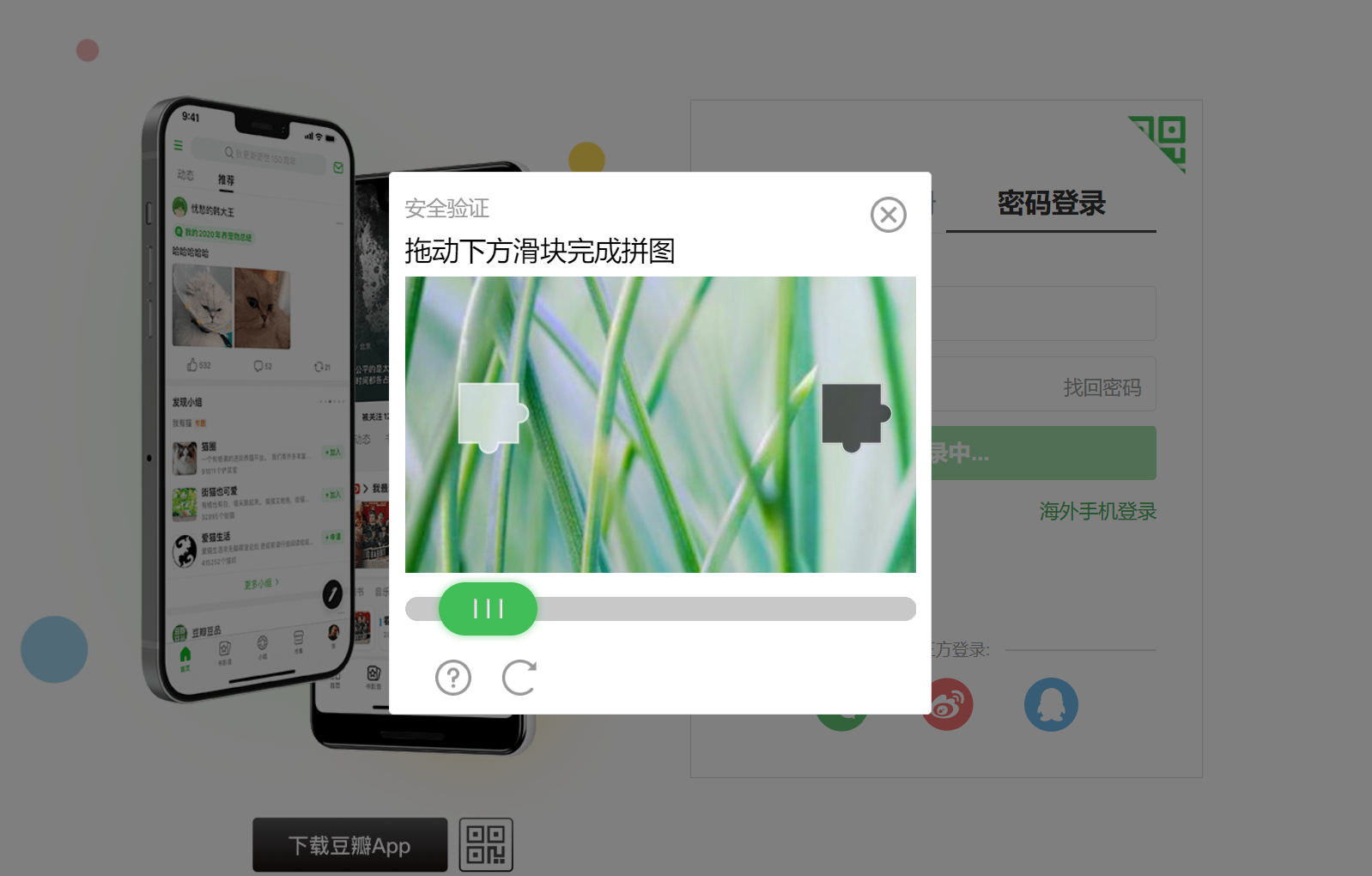
爬虫验证码破解(二):滑块验证码
1、前言 我们在进行爬虫的过程中,服务器经常为了校验是否是机器人操作,会使用验证码进行判断 常见的验证码格式: 数字字母验证码 滑块验证码 点字验证码 破解验证码的方式有: 光学文字识别:...

Selenium的进阶使用(二)
二、Selenium进阶使用 2.1 窗口的切换 2.1.1 切换到显式窗口 显式窗口:顾名思义,通过按钮的点击,可以直接打开一个新的窗口 前面提到点击事件click(),是在原窗口中更改网页,所以放打开一个...
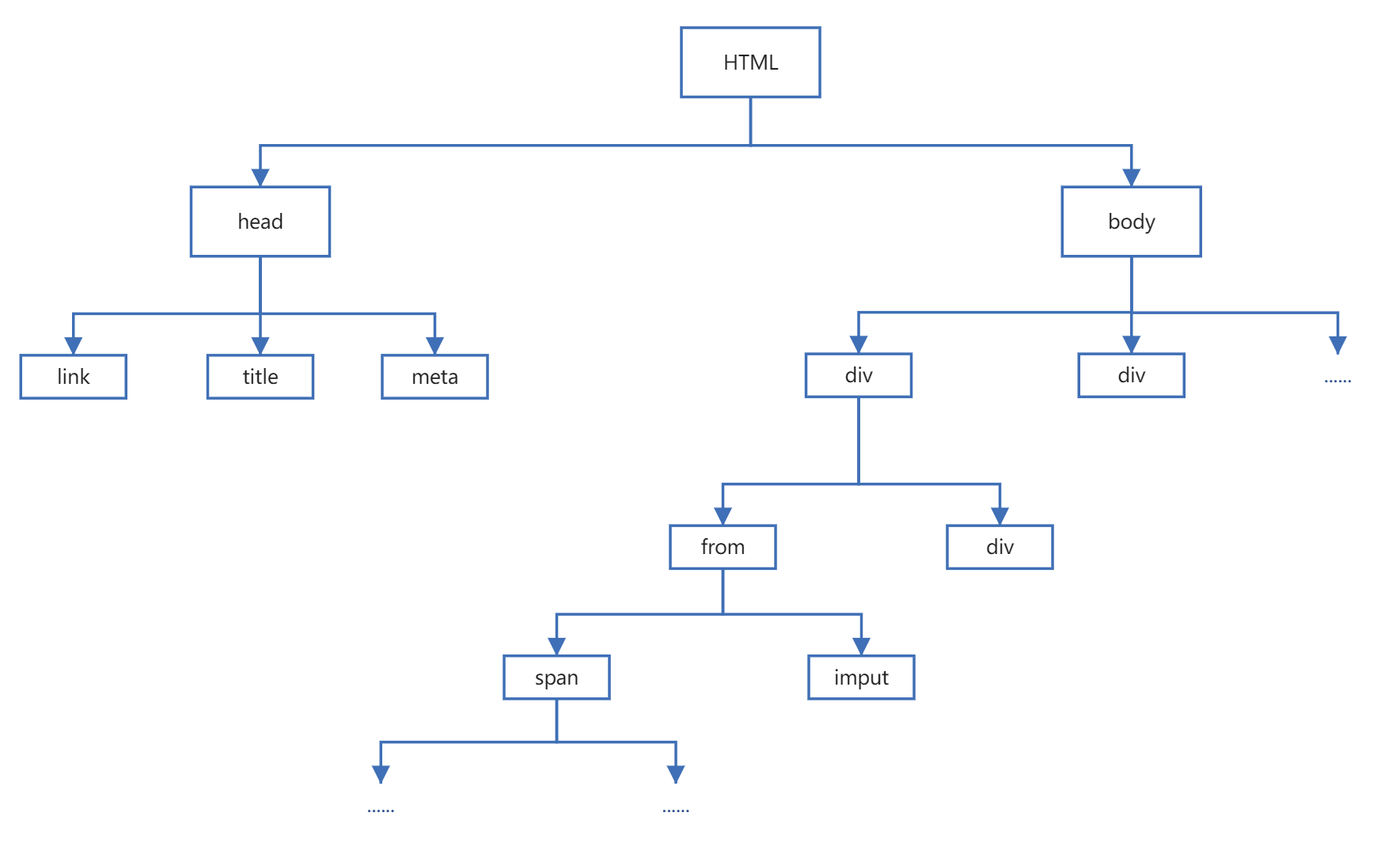
XPATH路径提取规则
一、XPATH 前面的学习中,学习了正则表达式解析,但是正则解析能用,但是相对比较麻烦;所有又学习了BS4解析,这是一个常用的方式,需要重点掌握,并且着重关注select和select_one以及配合使用c...

爬虫验证码破解(三):超级鹰破解
1、超级鹰介绍 超级鹰是沧州世纪鑫鹰信息技术有限公司旗下的互联网技术品牌,是国内领先的智能图片验证码 识别、图片分类平台!超级鹰旨在为广大客户提供即时、精准的图片验证码识别及图片分...

常见反爬及反反爬
一、常见反爬 1.1 简介 一切限制爬虫程序从服务器获取数据的方式都属于反爬虫。 它有多种限制手段,如:限制请求头、限制登陆、验证码检验、限制访问频率等。 从这些限制手段出发,可以将...

BeautifulSoup解析数据
一、BeautifulSoup4解析数据 正则可以解析任意的字符串,但是bs4专门用来解析网页的 Beautiful Soup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。官方解释如下: Bea...

爬虫简介&requests使用&正则解析数据
一、爬虫简介 1.1 什么是爬虫 爬虫,即网络数据采集,是数据分析的第一步:获取数据 简言之,爬虫可以帮助我们把网站上的信息快速、批量的提取并保存下来。 爬虫(crawler)也经常被称为网络蜘蛛(...

Requests请求动态数据
一、静态页面和动态页面 通俗来讲: 静态网页:网页的内容一经发布,除非再进行人为的修改,否则页面内容不会发生改变。 动态页面:虽然同样页面代码不发生变化,但是其显示的内容确实可以随着...
自动化测试工具Selenium
一、Selenium Selenium 是一个用于 web程序的自动化测试工具,直接运行在浏览器中,能够像真正的用户一样操作浏览器,也就是说,利用它可以驱动浏览器执行特定的行为,最终帮助爬虫开发者获...
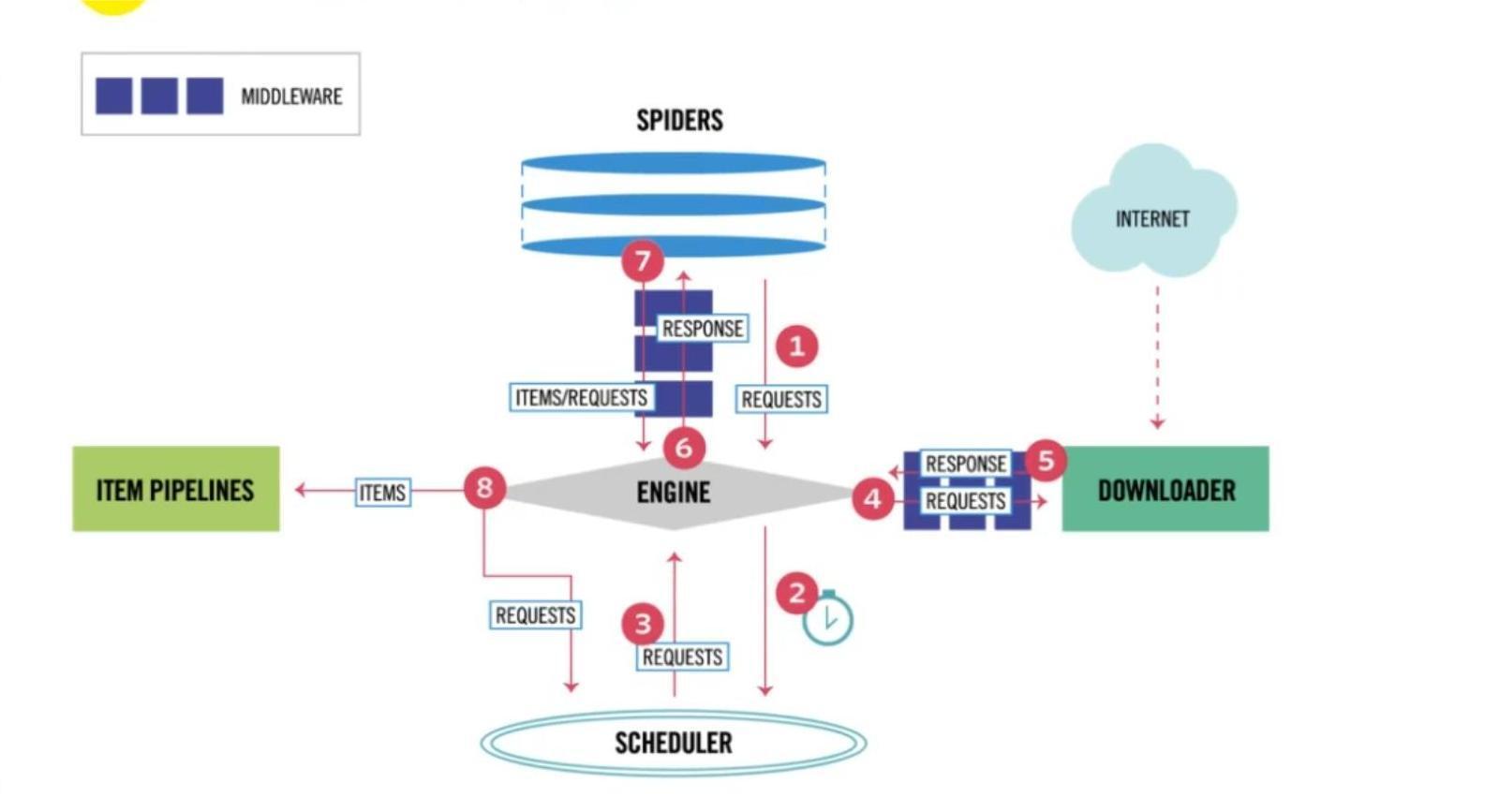
Scrapy框架的基本使用(一)
1、Scrapy概述 当我们写了很多个爬虫程序之后,你会发现每次写爬虫程序时,都需要将页面获取、页面解析、爬虫调度、异常处理、反爬应对这些代码从头至尾实现一遍,这里面有很多工作其实都是...