
爬虫共20篇
排序

Web前端简介&HTML&CSS&JS简介
一、Web前端简介 1.1 基本知识 网页主要由三个部分组成: 结构:负责网页的结构和内容,如:标题,图片,段落等,由html实现 表现(样式):设定网页的表现形式,如:标签的位置,大小,文字颜...
爬虫验证码破解(二):滑块验证码
1、前言 我们在进行爬虫的过程中,服务器经常为了校验是否是机器人操作,会使用验证码进行判断 常见的验证码格式: 数字字母验证码 滑块验证码 点字验证码 破解验证码的方式有: 光学文字识别:...

爬虫简介&requests使用&正则解析数据
一、爬虫简介 1.1 什么是爬虫 爬虫,即网络数据采集,是数据分析的第一步:获取数据 简言之,爬虫可以帮助我们把网站上的信息快速、批量的提取并保存下来。 爬虫(crawler)也经常被称为网络蜘蛛(...

爬虫验证码破解(三):超级鹰破解
1、超级鹰介绍 超级鹰是沧州世纪鑫鹰信息技术有限公司旗下的互联网技术品牌,是国内领先的智能图片验证码 识别、图片分类平台!超级鹰旨在为广大客户提供即时、精准的图片验证码识别及图片分...

BeautifulSoup解析数据
一、BeautifulSoup4解析数据 正则可以解析任意的字符串,但是bs4专门用来解析网页的 Beautiful Soup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。官方解释如下: Bea...
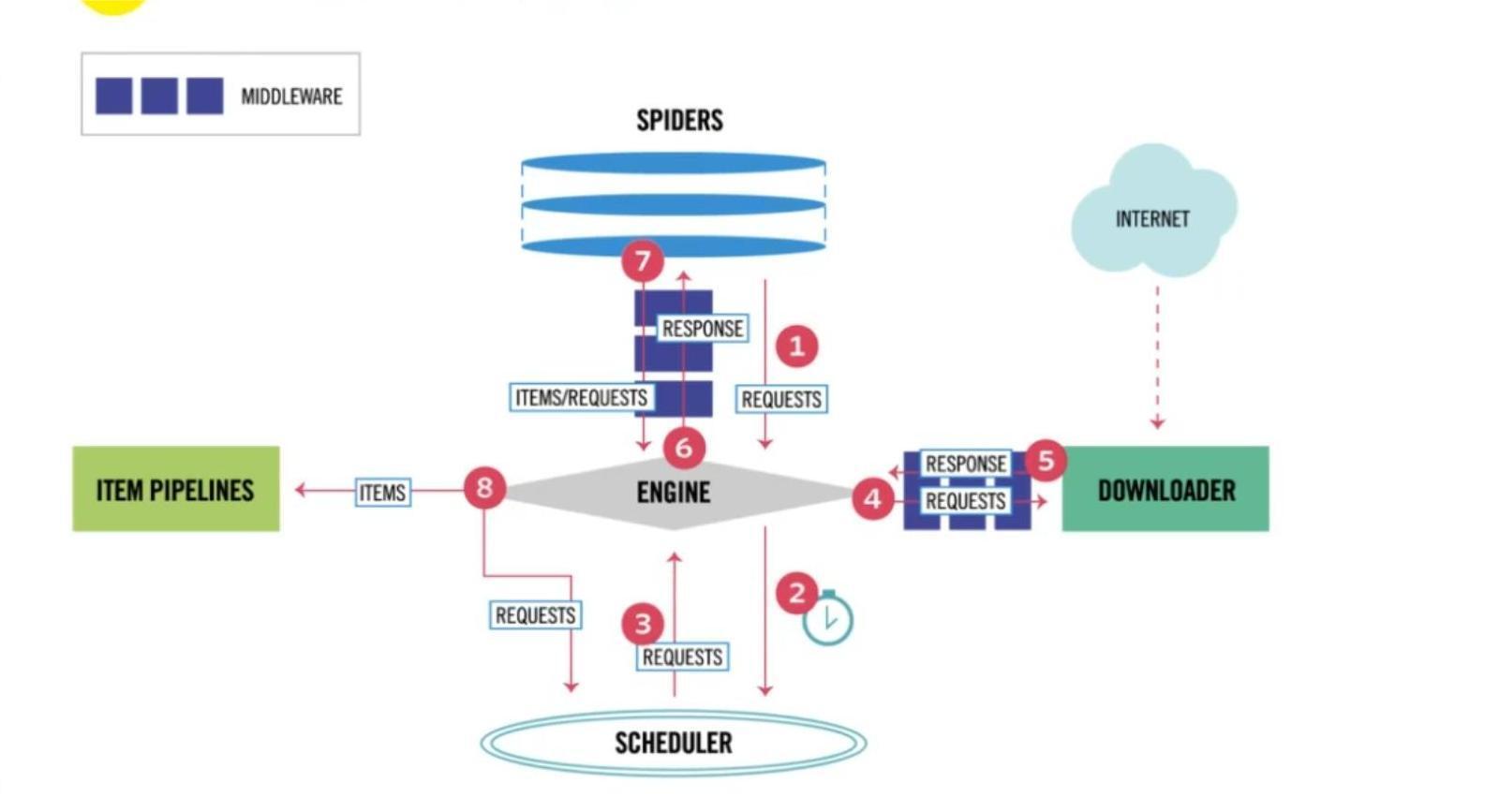
Scrapy框架的基本使用(一)
1、Scrapy概述 当我们写了很多个爬虫程序之后,你会发现每次写爬虫程序时,都需要将页面获取、页面解析、爬虫调度、异常处理、反爬应对这些代码从头至尾实现一遍,这里面有很多工作其实都是...

BeautifulSoup解析数据二
一、添加进度条 在解析多页数据的时候,可能时间比较长,我们可以给程序添加一个进度条,用来观察程序运行的状态 这个就需要用到一个第三方库tqdm 1.1 tqdm说明 tqdm是一个用来表示进度条的模块...
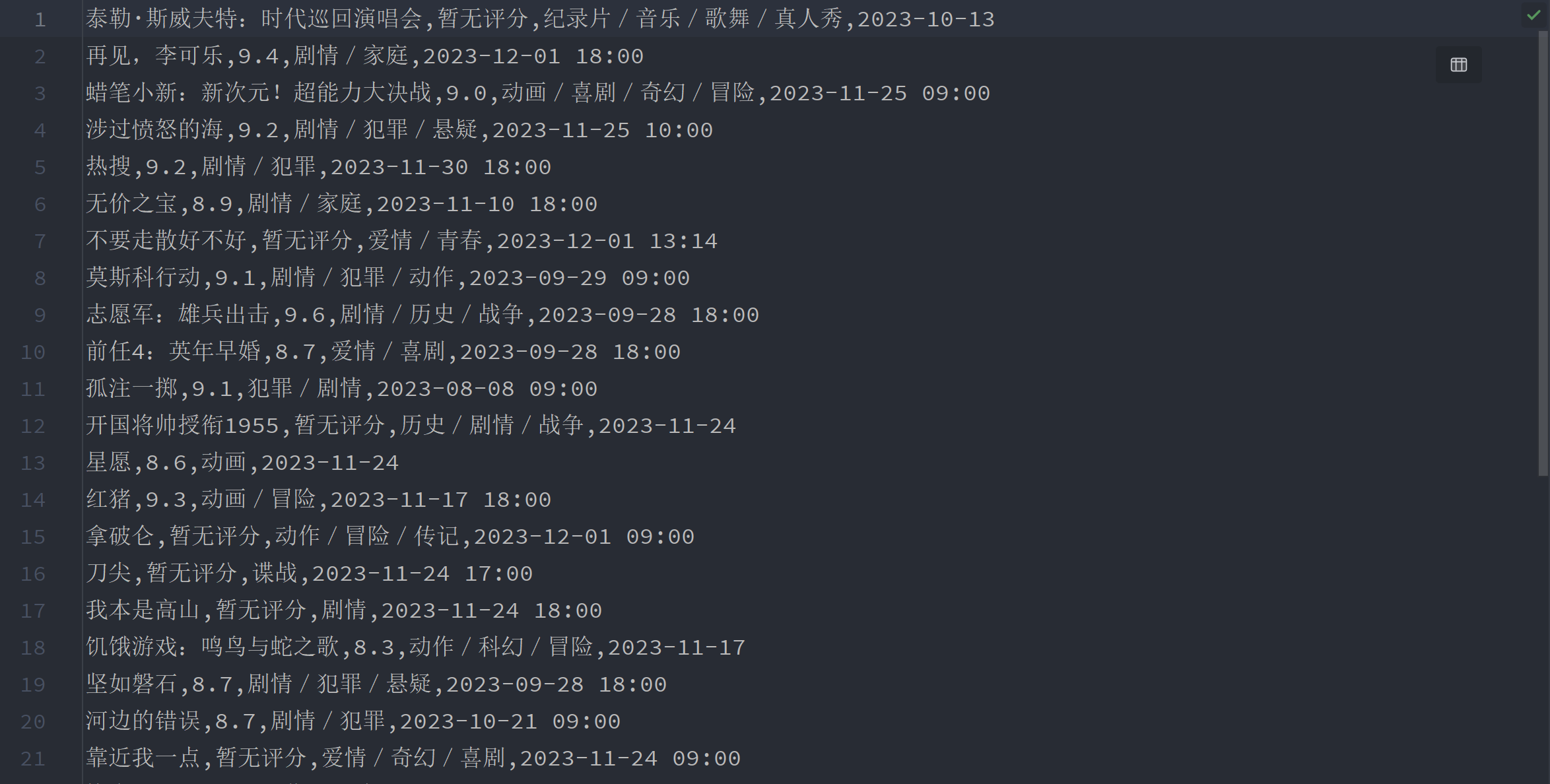
Spider练习(一):提取猫眼电影数据
一、需求 提取猫眼电影首页的数据,网站URL:https://www.maoyan.com/films?showType=3 提取'电影名称', '评分', '电影类型', '电影上映时间'四项内容,并且整理成[['泰勒·斯威夫特:时代...
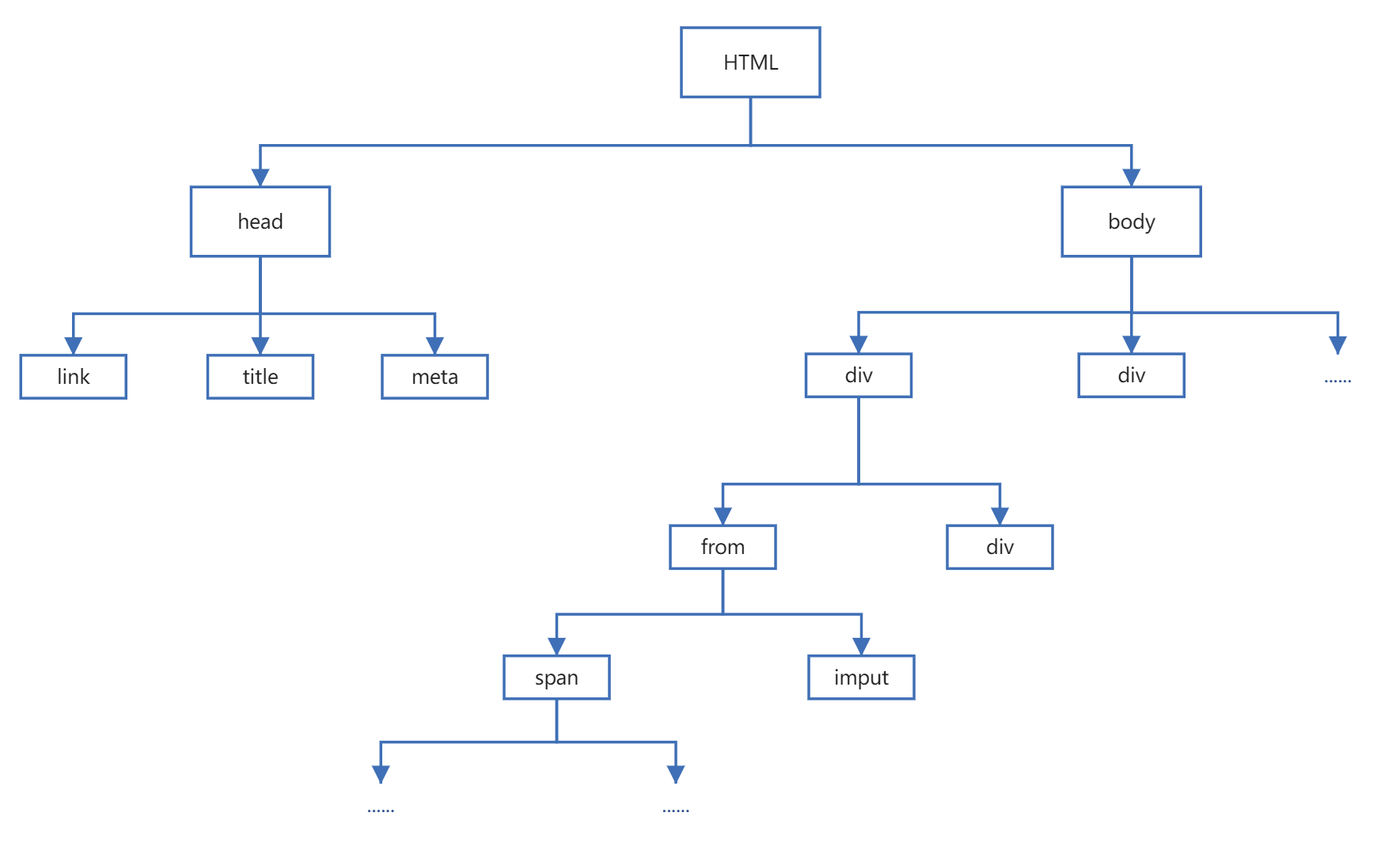
XPATH路径提取规则
一、XPATH 前面的学习中,学习了正则表达式解析,但是正则解析能用,但是相对比较麻烦;所有又学习了BS4解析,这是一个常用的方式,需要重点掌握,并且着重关注select和select_one以及配合使用c...
BS4解析案例:解析中国新闻网
一、BS4解析中国新闻网 1.1 需求 抓取中国新闻网及时新闻页面的内容,主要抓取”新闻类别“、”新闻标题“、”新闻时间“以及”新闻链接“,并且整理成 [['图片', '瑞士选手获女...